AI로봇
[Unity, 강화학습, MARL]AI vs AI, 강화학습 기반 Multi-agents 경쟁 시스템 개발
keep-steady
2023. 2. 21. 18:09
Introducing ⚔️ AI vs. AI ⚔️ a deep reinforcement learning multi-agents competition system
인공지능대 인공지능이 경기를 통해 스스로 학습하는 Multi-agent 강화학습 시스템을 만들어봅시다.
AI와 AI 두 agent가 서로 학습하고 경쟁하며 self-learning 합니다.
강화학습 기법으로는 기존 PPO나 SAC 말고 Unity에서 개발한 POCA를 사용합니다. PPO와 SAC에 비해 학습속도와 성능이 월등합니다.
Unity의 ml-agents를 사용하여 torch로 강화학습을 합니다.
직접 학습한 축구AI로 다른 사람들과 경기해 볼 수 있어요:)

1) Reference
2) 환경셋팅
- 2.1) Anaconda 환경이 세팅된 윈도우 노트북의 cmd 창에서 실행
conda create --name rl python=3.9
conda activate rl
mkdir rl
cd rl
git clone --branch aivsai https://github.com/huggingface/ml-agents
cd ml-agents
mkdir training-envs-executables
pip install -e ./ml-agents-envs
pip install -e ./ml-agents
pip install torch
pip install --upgrade protobuf==3.20.0
- 2.2) git-lfs 설치
- 2.3) 학습환경 모델 설정
- ml-agents/training-envs-executables/ 폴더에 아래 링크에서 다운받은 SoccerTwos 폴더 위치하기
3) 멀티 에이전트 강화학습 준비 (MARL 학습)
- Unity의 mlagents-learn을 실행시키고 2:2 축구 환경을 실행할 수 있도록 셋팅
- 학습을 위해서 4개의 파라미터 지정 필요
- mlagents-learn <config>: the path where the hyperparameter config file is.
- env: where the environment executable is.
- run_id: the name you want to give to your training run id.
- no-graphics: to not launch the visualization during the training.
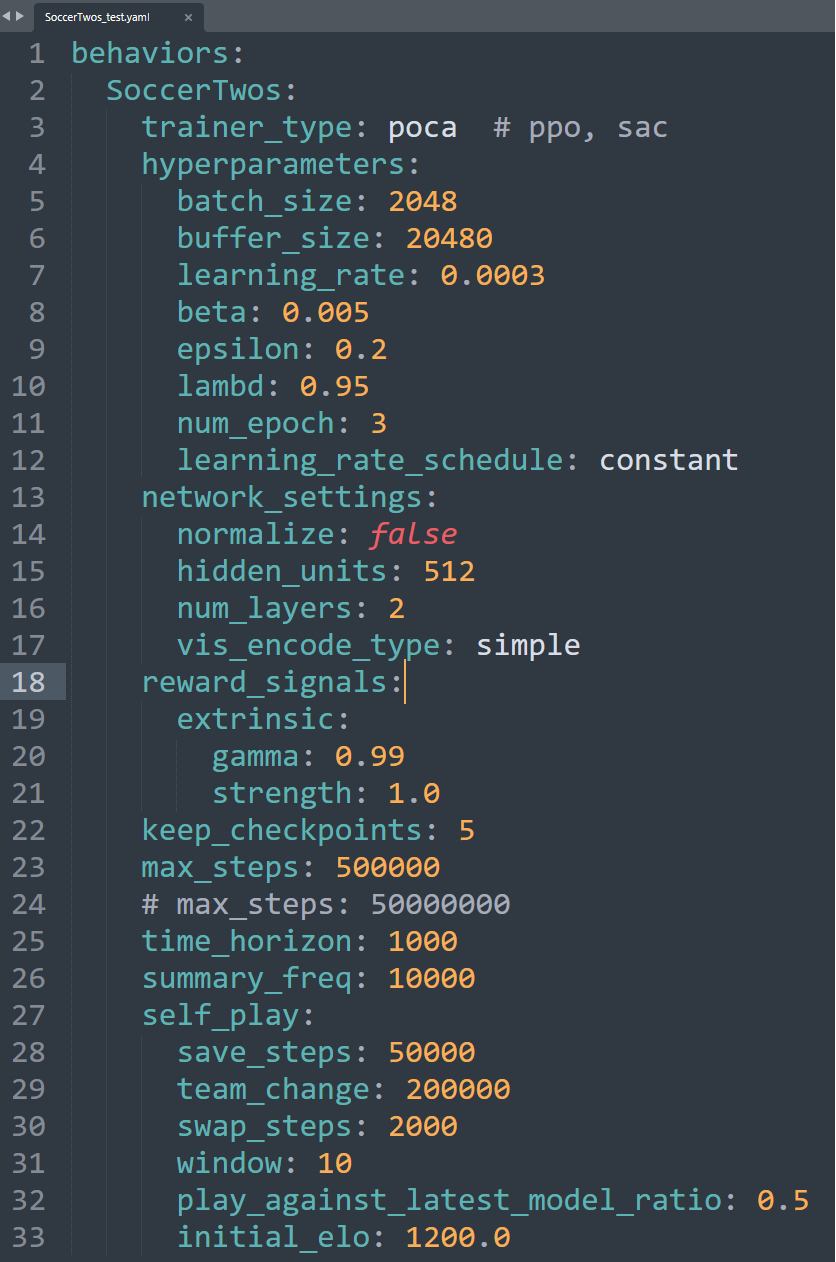
- 학습 파라미터 설정: config 폴더 내 yaml 파일 수정
- https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md 참조
- max_steps, 모델 크기, 학습률, 보상정책 등등 파라미터 수정 가능
- 학습방법 선택
- trainer_type: poca, ppo, sac 3가지 중 선택, poca 성능이 제일 월등
- Unity의 최신 강화학습 기법: POCA(https://arxiv.org/pdf/2111.05992.pdf)
- MA-POCA(Multi-Agent POsthumous Credit Assignment)
- Self-Play with an MA-POCA trainer (called poca)
- cooperative behavior and self-play to get an opponent team

- POCA 성능
- PPO, COMA에 비해 step 대비 보상이 높음, 즉 성능이 좋다

4) MA-POCA 이해하기
- 어떤 상황이지?
- 1 vs 1로 학습한다면 self-play를 하면 됩니다.
- 그런데 2 vs 2로 2개의 agent로 경기를 한다면?? 두 로봇이 협력 행동을 해야 합니다.
- 골을 넣는데 기여를 하지 않았어도, 골을 넣으면 모든 팀원이 보상을 받도록 설계
- 모든 그룹에게 좋은 행동이 되도록 학습
- 강화학습 정책(reward function)

- 강화학습 정책(observation space)
- 336차원 벡터
- 11 ray-casts forward distributed over 120 degrees (264 state dimensions)
- 3 ray-casts backward distributed over 90 degrees (72 state dimensions)
- Both of these ray-casts can detect 6 objects:
- Ball
- Blue Goal
- Purple Goal
- Wall
- Blue Agent
- Purple Agent
- 강화학습 정책(action space)

5) MARL 학습 시작(다중 에이전트 트레이너에서 솔루션)
- 5.1) 강화학습 정책
- 첫 번째 모델이 승리한 경우 1, 무승부인 경우 0.5, 두 번째 모델이 승리한 경우 0을 수집
mlagents-learn ./config/poca/SoccerTwos_test.yaml --env=./training-envs-executables/SoccerTwos.exe --run-id="SoccerTwos" --no-graphics --resume

- 5.2) 학습 완료

- 5.3) 결과파일 체크
- results/SoccerTwos 폴더에 'SoccerTwos.onnx' 파일 생성

6) Huggingface에 내 모델 업로드 하기
- 6.2) 토큰 발급 및 저장
- 내 HF 토큰: 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
- 6.3) cmd창에서 huggingface 접속
>> huggingface-cli login
>> <<내 토큰 입력>>
>> n

- 6.4) Huggingface에 업로드 명령어
>> mlagents-push-to-hf --run-id=<Add your run id> --local-dir=<Your local dir> --repo-id=<Your repo id> --commit-message="First Push"
>> (예시)mlagents-push-to-hf --run-id="SoccerTwos" --local-dir="./results/SoccerTwos" --repo-id="keepsteady/poca-SoccerTwos" --commit-message="First Push"

- 6.5) Huggingface 웹에서 업로드 확인
- https://huggingface.co/<<사용자ID>>

- 6.6) 업로드 파일 체크

7) 로봇축구 경기 시작!
- 7.2) Huggingface에 업로드된 모델들 중 내 모델 선택
- 내 huggingface 저장 hub에 'ML-Agents-SoccerTwos' tag가 붙어있어야 한다
- 7.3) 아래 Kick-off 클릭

- 7.4) 축구 실행 화면

- 7.5) Leaderboard 확인

Conclusion
Unity에서 2대 2 로봇축구를 Multi-agent 강화학습을 통해 서로 대결하며 학습하는 POCA 강화학습 기법을 사용하여 학습했습니다. 윈도우에서도 실행 가능하고 웹에서 바로 다른 참가자 모델과 경기가 가능합니다.