AI에서 이미지 공부할 때 MNIST만 돌려보는 건 지겹지 않은가??
이미지 분류 고급과정에선 아래와 같이 이미지 분류의 A to Z를 Hands-on 과정으로 다룬다.
1. 이미지 자동 크롤링
2. EfficientNet을 이용한 이미지 분류
3. GradCAM을 이용한 XAI(Explainable AI)
4. 적대적 공격(Adversarial attack)으로 내 모델 공격하기
그중 첫 번째, 이미지 자동 크롤링!
- 목적: 이미지 분류를 위한 데이터셋을 만들자
- 순서
1) 분류하고자 하는 클래스(class) 정하기
- 개 or 고양이
- 사과 or 딸기
2) 구글&네이버에서 지정한 클래스를 폴더별로 다운로드
(https://keep-steady.tistory.com/28)에서 네이버 이미지 크롤링을 다뤘다.
그런데 스크롤을 내리는 작업이 구현되지 않아 50개까지 밖에 크롤링이 되지 않는 한계가 있었다.
그래서 크롬 드라이브를 이용하여 구글, 네이버에서 자동으로 스크롤도 내리고 링크를 받아서 다운로드하여주는 크롤러를 수행하 보자. 실행하면 아래와 같이 저절로 크롭웹창이 열리고 구글&네이버에서 검색어가 입력된다. 아래로 자동 스크롤이 되며 링크를 저장한다. 저장된 링크들을 모아 사진을 다운로드한 후 'downloads' 폴더에 저장한다.

Hands-On 시작!

1) Chrome 설치
- 본 실습은 Chrome을 이용한다. python에서 웹을 제어하기엔 Chrome이 제일 편하다. 아래 링크에서 다운받은 후 크롬을 설치하자.
- https://www.google.com/intl/ko/chrome/
2) 크롤링 프로그램 다운로드
- Terminal에서
>> git clone https://github.com/YoongiKim/AutoCrawler
>> cd AutoCrawler
- 윈도우에서
링크(https://github.com/YoongiKim/AutoCrawler) 다운로드한 후 앞축 풀기
3) 크롤링에 필요한 패키지 설치
>> pip install -r requirements.txt
4) 다운로드할 키워드 입력
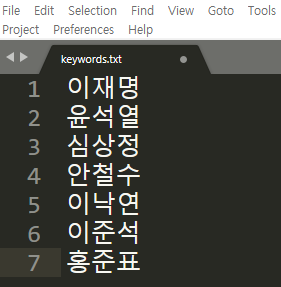
AutoCrawler-master 폴더 안의 keywords.txt을 연다.
검색하고 자 하는 키워드를 한 줄에 한 개씩 쓴 후 저장한다.
5) 크롤링 실행
터미널 창에서 크롤링 프로그램 실행. 무제한으로 크롤링 되며 대략 1000개씩 다운로드 된다.
>> python main.py
5-1) 테스트로 20개씩만 돌려서 잘 돌아가는지 체크해 보자
>> python main.py --limit 20
6) 크롤링 결과 확인
- download 폴더에 한 검색어 당 약 1000개씩 다운받아 진것을 확인한다. 엄청 많은 사진을 긁어오므로 시간이 꽤 걸린다. 실행해놓고 차 한잔 하고 오면 짜잔~ download 폴더에 클래스 별로 폴더가 만들어진다.
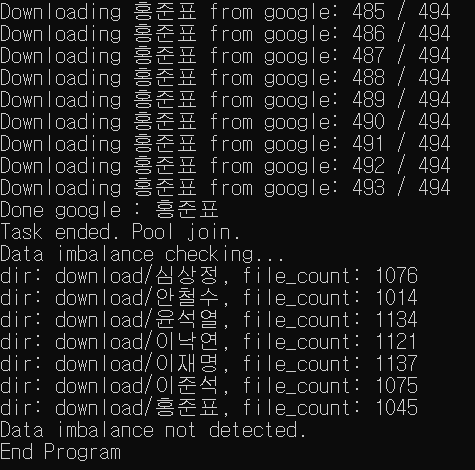

각 클래스 폴더를 들어가면 대략 1000개 정도씩의 이미지가 다운받아졌다.
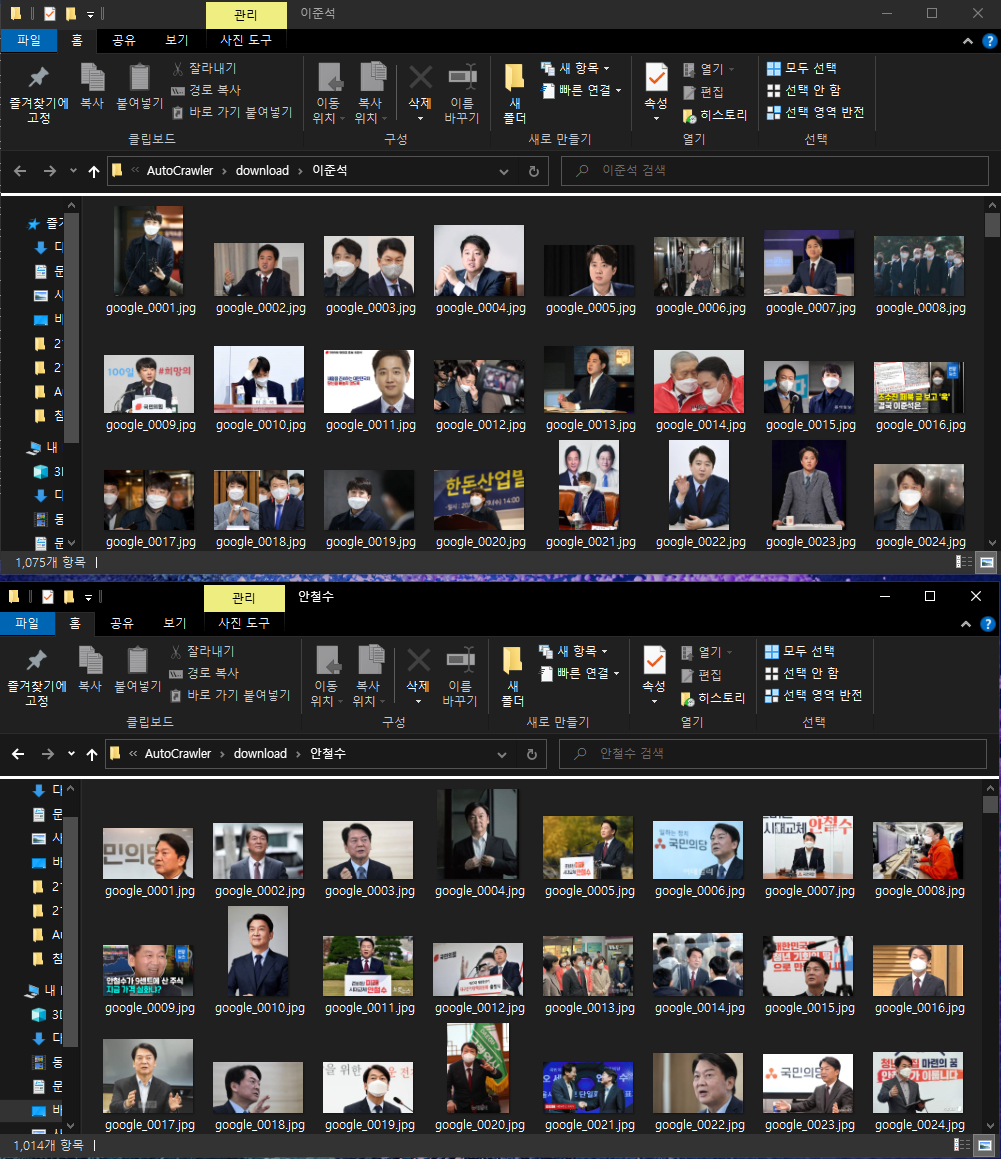
7) 데이터 정제
- 이미지 분류 데이터셋을 만들기 위해선 한 사진에 클래스에 속하는 두 인물이상이 있으면 안된다. 예를들어 single label classification이기 때문에 입력 이미지에서 '이준석'과 '안철수'가 동시에 있다면 둘중 한개의 class밖에 설정할 수 없다. 이러한 문제를 해결하기 위해서는 multi-label classification 모델로 문제를 해결하면 된다.
우선 본 프로젝트는 single-label classification이기 때문에 입력 이미지에 한개의 class만 존재하도록 삭제한다. 학습에 악영향을 끼칠 거 같은 사진들은 과감하게 지워주자. 그아무리 좋은 딥러닝 모델을 쓰는것보다 지금 이 정제과정이 가장! 중요하다!! 쓰레기가 들어가면 쓰레기가 나온다. 좋은 양질의 데이터가 중요하다!!
데이터 정제를 통해 3시간 동안 모든 사진을 보면서 노이즈를 제거했다.
- 이재명: 1137->821
- 윤석열: 1134->898
- 심상정: 1076->910
- 안철수: 1014->855
- 이낙연: 1121->739
- 홍준표: 1045->860
- 이준석: 1075->904
Conclusion
이번 장에선 직접 내가 원하는 클래스의 이미지를 크롤링하는 법에 대해 알아봤다. 딥러닝을 위해선 많은 양의 데이터가 필수이다. 한 클래스당 적어도 500개 이상의 데이터가 필요하다. 하지만 이렇게 웹에서 수집한 데이터는 노이즈가 많다. 꼭 데이터 정제를 수행해서 양질의 데이터셋을 구축하자.
다음장에선 이미지 분류 최고 알고리즘인 EfficientNet로 분류 모델을 실습할 거다. 직접 크롤링한 이미지로 학습해보자!! 고고씽~
'AI > 영상인식(Vision)' 카테고리의 다른 글
| OCR 정리 (1) | 2020.06.24 |
|---|---|
| (이미지 분류 고급) 2_EfficientNet을 이용한 대선후보 분류 Hands-On (18) | 2020.06.15 |
| 1) 이미지 분류 따라해보기 : 네이버 데이터 크롤링! 20초면 끝 -50개까지만 가능 (0) | 2020.05.25 |

