5분만에 H2O AutoML을 끝장내보자. 사실 5분도 안걸린다. 구글 Colab에서 바로 사용할 수 있다.
Github 주소 : github.com/keep-steady/automl_h20_practice_python
실습 colab 주소 : colab.research.google.com/drive/1oRIdDWNL_NMdwmGmrS8rK0KiJOdtt5MH?usp=sharing
=> colab을 연 후 아래 그림과 같이 data.csv를 기본 경로에 업로드

AI프렌즈 김** 선생님께서 아주 좋은 데이터를 공유해주셨다.
여러 가지 feature를 이용하여 서류 합불을 예측할 수 있는 데이터이다.
최근 AI프렌즈에선 AutoML에 관심 있는 사람들이 많다.
나는 작년 NAS 논문 몇 개 읽어 보고 코드 한번 돌렸다가 며칠간 결과가 나오지 않아 중간에 끈적이 있어서
NAS나 AutoML에 대해선 부정적이었다.
이번 계기로 공부해보면서 미래에 진짜 AutoML이 내 일자리를 뺏을까? 생각해보고 향후 어떤 방향으로 연구해야 할까 고민해보려 딱 3시간만 보자 마음먹었다.
'그사이 많이 좋아졌나??' 하는 마음으로 코드를 공유받았다.
그런데 문제가 있었다. R로 짜져 있었다....!!!
'그 언어가 그 언어지 뭐'라 생각했지만 R은 신세계였다. 이상한 화살표(<-)가 계속 나온다
VSCODE에서 돌리려 했지만 pacman 설치에서 막혔다.
내가 pacman과 R을 공부해서 이 코드를 이해할까? 아님 그냥 파이썬으로 다시 짤까? 고민하다가
파이썬으로 처음부터 짜자고 마음먹었다.
h2o 공식 문서 링크 : docs.h2o.ai/h2o/latest-stable/h2o-docs/index.html
1. 설치
h20는 java로 만들어진 AutoML 라이브러리다. R, python에서 모두 동작한다. 설치는 간단하다.
필자는 윈도우에서 pip로 설치했다. 아래 명령어로 간단하게 설치할 수 있다.
# 종속 패키지 설차
pip install requests
pip install tabulate
pip install "colorama>=0.3.8"
pip install future
# 기존 h2o 삭제
pip uninstall h2o
# h2o 설치
pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2ojava로 돌아가므로 윈도우에서 java를 설치하라는 에러가 나올 수 있다.
현재 java 최신 버전은 15 버전인데 h2o는 java 8~14 버전만 호환이 가능하다. 그러므로 아래 링크에서 11 버전을 설치하면 사용 가능하다.
www.oracle.com/java/technologies/javase-jdk11-downloads.html

2. 각종 라이브러리 load
아래 코드로 본 실습에서 사용할 각종 라이브러리를 로드할 수 있다. h2o를 이용하기 위해선 h2o를 import 한 후
h2o.init() 을 통해 h2o 인스턴스를 생성한다. 기본 localhost의 54321 port에 생성된다.
#### 1. h2o 분석 준비하기 ####
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import time
import h2o
from h2o.automl import H2OAutoML
from h2o.estimators.gbm import H2OGradientBoostingEstimator
%matplotlib inline
h2o.init()
h2o.no_progress()성공적으로 h2o가 load 되면 아래와 같이 출력된다. successful을 확인하자.

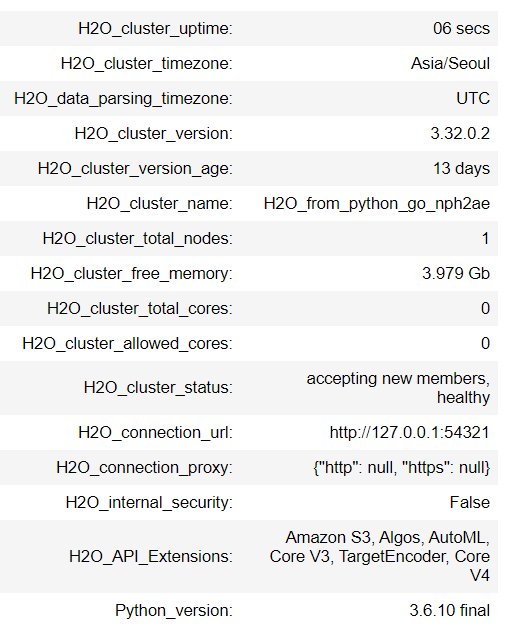
아래 표도 같이 출력된다. h2o에서 사용할 클러스터의 가동 시간, 시간대, 버전, 버전 수명, 클러스터 이름, 할당된 하드웨어 리소스 (노드 수, 메모리, 코어 수), 연결 URL, 노출된 H2O API 확장 및 사용된 파이썬 버전 정보가 출력된다. Amazon S3를 사용하고 13일 후에 이 인스턴스는 사라진다. 클러스터의 토털 노드 개수는 매번 달라졌다. 점심쯤 8개가 잡혔는데 지금은 1개가 잡힌다.
3. 데이터 불러오기
본 실습에선 김** 선생님이 제공해주신 학생들의 feature와 서류 합불 여부인 label을 사용했다.
pandas를 이용하여 'data.csv'를 읽어온 후 데이터를 확인한다.
#### 2. 데이터 불러오기 ####
data_df = pd.read_csv('data.csv')
data_df.head()
# 데이터 확인
data_df.describe()
# var2~는 입력 feature
feature = data_df.drop('var1', axis=1)
feature.describe()
# var1은 label
label = data_df['var1']
label.describe()
데이터는 아래와 같이 생겼다. var1부터 var103개까지 총 103개의 feature로 이루어져 있다. 각 value는 숫자이다. 이 중 'val1' colume이 합격/불합격을 나타내는 label이다.

4. h2o AutoML 시작
AutoML을 위해서 여러 가지 타입의 학습 세팅이 존재한다. 그중 가장 중요한 건 max_runtime_secs이다. 이는 몇 초간 탐색을 진행할 것인가의 변수고 30으로 설정하면 30초간 탐색, 120로 설정하면 120초간 탐색한다.
4.1. 데이터 준비 for h2o
y는 합격/불합격을 나타내는 'var1'이다. 다른 feature를 이용하여 var1을 맞추는 문제이므로 label에 해당한다.
x는 데이터 중 입력 colume을 나타내는 list이다. 그래서 데이터 프레임의 colume 값 중 'var1'을 제거한 list를 만든다. ex) x = [var2, var3, ....var103]
전체 데이터 수가 63개로 굉장히 작다. 이를 train/valid 데이터 셋으로 나누기 위해 sklearn의 train_test_split 함수를 이용했다. 8:2로 나누기 위해 test_size를 0.2로 설정했고 shuffle을 통해 골고루 섞이도록 했다.
여기까진 일반 ML과 같은데 지금부턴 h2o를 위한 세팅이다. h2o.H2OFrame 함수를 이용하여 h2o에서 사용하기 위한 자체 데이터프레임을 구축한다. 그냥 이 함수를 통과하면 된다. 편한 듯 하지만 나중에 이 자체 데이터프레임으로 인해 list나 값을 추출하는 게 굉장히 불편하고 잘 되지 않는다.
맨 밑 2줄은 데이터 중 label이 어떤 colume에 해당하는지 알려주는 .asfactor() 함수이다.
################################################################
## make dataset
# Identify the response and set of predictors
y = "var1"
x = list(data_df.columns) #if x is defined as all columns except the response, then x is not required
x.remove(y)
# data_df을 8:2로 나눈다, 50 : 13
train, valid = train_test_split(data_df,
test_size=0.2,
shuffle=True)
h2o_train = h2o.H2OFrame(train)
h2o_valid = h2o.H2OFrame(valid)
# For binary classification, response should be a factor
h2o_train[y] = h2o_train[y].asfactor()
h2o_valid[y] = h2o_valid[y].asfactor()
4.2. h2o 학습
진짜 딱 2줄로 AutoML이 된다. 허허 단 두줄이라니. R에선 심지어 한 줄이었다.
H2OAutoML 함수에 최대 몇 초간 탐색을 할 것인지, 그리고 어떤 알고리즘은 제외할 것인지를 선언한다. 김 선생님이 제외한 XGBoost와 StackedEnsemble은 제외했다.
그리고 대망의 학습 코드. x는 데이터의 colume 중 feature 명, y는 label 명이다. training_frame은 학습 데이터를, leaderboard_frame은 검증 데이터를 입력으로 받는다. 왜 leaderboard라고 했을까? 직관적이지 못하다. 그냥 train_dataframe, valid_dataframe으로 하는 게 더 나을 거 같은데.
################################################################
## Run AutoML for 120 seconds
aml = H2OAutoML(max_runtime_secs=max_runtime_secs, exclude_algos =['XGBoost', 'StackedEnsemble'])
aml.train(x = x, y = y, training_frame=h2o_train, leaderboard_frame=h2o_valid)
이게 끝이다. 그럼 지정한 max_runtime_secs 동안 탐색 후 최고의 모델을 알려준다.

학습을 하는 동안 위와 같은 경고가 나온다. GBM 모델을 돌리기에 데이터 개수가 최소 100개는 돼야 되는데 50개밖에 안돼서 불가능하다는 내용이다. 무시하고 넘어가면 된다. 현 데이터에 최적의 결과를 내는 모델을 찾는 게 목적인데 데이터가 적어서 안된다면 그 모델은 탈락이다.
4.3. h2o 학습 결과 저장
학습이 끝나면 사용한 aml 함수에 leaderboard와 leader를 통해 학습 결과를 고찰할 수 있다.
아래 코드를 통해 중요 metric을 저장하고 출력해보자.
정확도, precision, recall, f1, auc 등을 알 수 있고 이 밖에 훨씬 더 많은 metric을 확인할 수 있다. 나는 주로 정확도와 f1만 쓰는데 정말 metric이 많다. 각자 데이터에 맞는 metric을 선정하여 그것을 기준으로 최고의 모델을 선정하자. variable_importance는 어떤 입력 feature가 결과에 많은 영향을 미쳤는가를 나타낸다.
################################################################
## save metric
# Print Leaderboard (ranked by xval metrics)
leaderboard = aml.leaderboard
performance = aml.leader.model_performance(h2o_valid) # (Optional) Evaluate performance on a test set
model_id =aml.leader.model_id # 최고 모델 명
accuracy =performance.accuracy() # 정확도
precision =performance.precision() # precision
recall =performance.recall() # recall
F1 =performance.F1() # f1
auc =performance.auc() # auc
variable_importance=aml.leader.varimp() # 중요한 입력 변수
print(model_id, accuracy, precision, recall, F1, auc, variable_importance)
print(performance)
performance를 출력하면 정말 많은 정보가 나온다. MSE, RMSE, AUC 등을 확인할 수 있고 Confusion matrix도 자동으로 나온다.

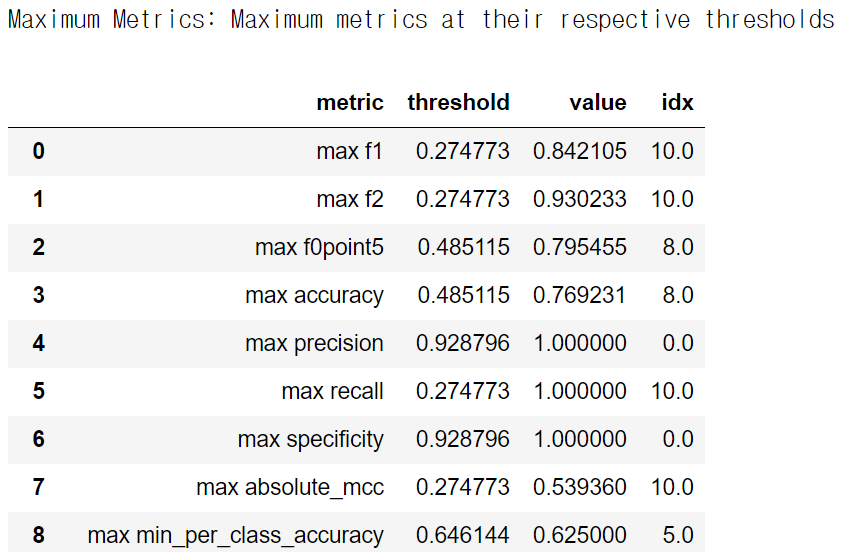
아래 표와 같이 f1 중 가장 높은 값과 정확도 값 등이 나온다. 이 중 원하는 idx의 모델을 선택해서 쓰면 된다.
5. 학습한 모델 및 variable importance 확인
아래 코드로 모델의 중요 변수를 시각화할 수 있다. 아래 그림을 보면 h2o로 학습한 최강 모델 GBM은 결과를 도출하는데 var100, var12, var7, var23이 가장 큰 영향을 받는다고 한다. 그럼 저 항목이 어떤 건지 알 수 있다면 카이스트 서류합격을 위해 저 두 개를 중점적으로 준비해야겠다는 전략을 세울 수 있다. 필자도 카이스트 출신으로 저 두 항목이 뭔지 상당히 궁금하다ㅎㅎ
## 중요 변수 시각화
aml.leader.varimp_plot()
## automl 결과 확인
# Get AutoML object by `project_name`
get_aml = h2o.automl.get_automl(aml.project_name)
# Predict with top model from AutoML Leaderboard on a H2OFrame called 'test'
label_predicted = get_aml.predict(h2o_valid)
print(label_predicted['predict'])
print(h2o_valid['var1'])

결론
R로 된 h2o 코드를 파이썬에서 동작하도록 변형시켰다. 주관적인 생각은 h2o는 파이썬에서 쓰기 힘들다. h2o의 내장 데이터프레임이 내부의 결과 value를 외부로 빼는 게 어렵고 30분을 애썼지만 결국 방법을 못 알아냈다. 뭔가 방법이 있겠지만 퇴근해야 한다. 그리고 kappa 변수 등 R에서 쉽게 구할 수 있던 변수는 파이썬에서는 구할 수 없었다. h2o를 아주 깊고 완벽하게 사용하고 싶다면 파이썬보단 R을 추천한다. 필자는 R을 모르므로 딱 여기까지만 하려 한다.
탐색 시간을 길게 하고, for문으로 여러 모델을 학습해보며 가장 최적의 모델을 찾아내는 건 의미가 있어 보인다. 하지만 모델이 가볍고 작아야 많은 모델을 주어진 시간 동안 탐색할 수 있으므로 간단한 모델밖에 수행할 수 있다. 또 tabular 형식 데이터에 한해서만 가능한 방식이다. NLP나 음성 데이터는 이러한 접근방식이 불가능하다. 언젠가 비정형 데이터도 AutoML이 가능해질 날이 오겠지.
가끔 'NAS와 AutoML이 등장해 AI도 AI가 해서 AI전공자가 실직자가 되는 시대가 올 것이다!!!'라는 얘기를 종종 듣곤 한다. 하지만 아직은 멀었다. 이 글을 작성하는 지금 세바시 김성 교수님이 '대체되기 어려운 창의적인 것을 해야 한다'라고 말씀하신다. AI를 하는 분들도 AI에 대체되지 않기 위해선 tabular 데이터만 다루기보다 AI가 하기 힘든 비정형 데이터를 다룬다면 몇 년은 더 늦게 대체되지 않을까.
Reference
docs.h2o.ai/h2o/latest-stable/h2o-docs/index.html
'AI > 데이터 분석' 카테고리의 다른 글
| 이번주 로또번호는? 로또번호 데이터 분석 (2) | 2020.05.07 |
|---|
