TransCoder(Unsupervised Translation of Programming Languages)
Link : https://arxiv.org/pdf/2006.03511.pdf
github: https://github.com/facebookresearch/TransCoder
참고 : https://www.facebook.com/monthly.nlp/posts/258096098955595/
5월 Facebook AI Research에서 Transcoder Transcoder라는 별칭의 코드 번역기가를 공개했다. 비지도 학습 기반 번역 기법을 프로그래밍 언어 간 변환에 적용한 연구이다. 아래 그림은 TransCoder 예시이다. 본 글에서는 Transcoder에 대해 다룬다.

Abstract
1. 자연어처리 번역 기술을 도입하여 서로 다른 프로그래밍 언어 간 변환에 적용한 Transcoder 개발
2. 비지도학습 접근방식으로 프로그래밍 언어 간 병렬 데이터 없이 저비용 언어 변환 기술
- 소스&타겟 코드 전문지식 필요 없음
- 쉽게 다른 코드로 일반화 가능
3. 코드별 변환율은 67.2%에서 91.6%까지 편차
Introduction
코드 변환 기술은 서로 다른 프로그래밍 언어를 변환하는 기술이다. 예를들어 C++로 짜인 코드를 같은 동작을 하는 Python 코드로 변환시키는 기술이다. 이 기술은 상호 운용성을 위해 구식 언어(ex, Python 2.7)로 작성된 코드나 더 이상 사용되지 않는 언어(ex, COBOL)로 작성된 코드를 현대 언어로 바꿔주기 위해 사용된다.
기존 코드베이스를 최신 또는 효율적인 언어(Java, C++)로 변형하려면 두 소스 언어의 전문지식이 필요하고 많은 비용이 든다. 예를들어 Commonwealth Bank(Australia)는 COBOL(사무 지향 보통 언어) 언어에서 Java로 변환하는데 5년간 9,000억이 들었다. 하지만 코드변환 기술을 도입하면 전체 코드를 맨처음(scratch)부터 재구축(rewriting)하지 않고 코드변환 모델로 변환 후 ‘적용’시키면 시간을 단축하고 비용을 절약할 수 있다. 최근 전문 번역가들도 NMT(Neural Machine Translation)로 자동 번역을 수행한 후 수정하는 비율이 높아지고 있다. 미래에 코드변환 프로젝트에서도 이런 현상이 일어날 거라 예상한다.
하지만 기존 방식은 handcrafted로 재작성된 규칙으로 소스코드 추상 구문 트리(Abstract Syntax Tree, AST)에 적용한다. 그래서 이 결과는 불행히 가독성 부족, 대상 언어 규칙 준수 실패, 작동을 위해 직접 변형이 필요하다. 이 모든 과정은 많은 시간이 소모되며, 소스 프로그래밍 언어와 타겟 프로그래밍 언어를 모두 잘하는 전문가 필요하여 코드번역 프로젝트는 많은 비용이 든다. 그래서 이 분야에 딥러닝을 적용하려는 시도가 있지만 소스와 타겟 코드의 병렬데이터가 부족하여 연구가 제한적이다.
이러한 문제들을 해결하기 위해 본 연구는 최신 비지도학습 기반 번역기술을 코드변환에 적용한 TransCoder를 개발하였다. 비지도학습 기반 번역기술은 소스와 타겟 언어의 병렬데이터가 없이도 번역모델을 개발하는 방법이다. 물론 지도학습 기반 번역 모델이 월등히 성능이 좋지만 병렬 데이터를 구축하는 자체가 고비용에 많은 시간이 걸려 불가능에 가깝다. 비지도 학습을 이용하면 소스와 타겟 언어의 전문지식이 필요 없고 쉽게 다른 언어를 추가하는 일반화도 가능하다.
Related work
1. 코드 변환
예전 통계기반 번역 기술을 Java<->C#나 Python2<->Pyrhon3 병렬 데이터로 학습한 경우가 있다. 하지만 이 연구들은 병렬 데이터를 구축해야 하는 지도학습 방법이고 BLEU(n-gram 일치도)를 평가 수치로 사용하여 실제 적용에 의문이 든다. 같은 동작을 하는 코드일 지라도 코드의 구성이 다르면 적은 BLEU 점수를 얻는데 이는 코드 평가에 적합하지 않다.
2. 코드 번역
번역 기술을 이용하여 파이썬 코드를 슈도코드로 변환한 연구와 Java 코드를 docstrings(함수 설명 주석)로 변환한 연구가 있다.
3. 다른 응용
binary programs을 C코드로 변환한 연구와 대량의 GitHub 코드를 BERT 언어모델로 학습하여 다양한 코드 관련 임무를 수행한 연구가 있다.
4. 비지도 학습 기반 번역 기술
번역 기술은 고품질의 병렬 데이터에 의해 성능이 영향을 받는다. 하지만 단일 언어 데이터에 비해 병렬 데이터는 거의 없거나 존재하지 않는다. 예를 들어 영<->한 번역인 경우 한 문장(12 단어)(12단어) 번역에 1,200원 정도, 10만 문장에 1.2억이 소요된다. 괜찮은 품질의 번역 모델을 만들기 위해서는 300만 문장의 병렬 데이터가 필요하다고 알려져 있는데, 이를 구축할 시 3636억 원이 소요된다. 즉 병렬 데이터 구축은 많은 비용이 들고 현실적으로 불가능하다.. 그래서 이러한 문제를 극복하기 위해 대량의 단일 언어 데이터로 사전학습하여 성능을 올린 비지도학습 기반 번역 기술이 발달하였다.
Model
TransCoder는 자연어처리의 번역/요약/챗봇에 사용되는 sequence-to-sequence 모델을 사용한다. 이 모델은 encoder-decoder 모델이라고도 불리는데 Transformer (Attention is all you need, https://arxiv.org/abs/1706.03762) 구조가 가장 좋은 성능을 낸다고 알려져 있다. Transformer 모델을 기반으로 3가지 방식으로 모델을 학습한다.
1. Cross Programming Language Model pretraining(CLM)

TransCoder는 XLM의 사전학습 방법을 사용한다. XLM 모델은 3절에서 자세히 다뤘으므로 생략한다.
TransCoder는 병렬 코퍼스가 아닌, 단일 언어 코드 데이터 3종으로 학습한다. 각 배치는 서로 다른 언어로 구성(C++, Java, Python)되어 배치 별 한 언어만 MLM으 학습하도록 했다. MLM이란 Masked Language Model의 약자로써 입력 문장에 임의로 빈칸(mask)을 뚫고 빈칸을 맞추는 학습을 하는 방식을 지칭한다. 문맥을 파악하여 빈칸을 채우는 문제이다. 첫 번째 배치에선 Masked 된 C++, 두 번째 배치에선 Masked 된 Java, 세 번째 배치에선 Masked 된 Python 언어 식이다.
XLM과 같은 Cross-lingual 모델들은 서로 다른 언어에서 공통적으로 등장하는 토큰(Anchor points)이 많을수록 효과적으로 벡터를 학습할 수 있다. 프로그래밍 언어의 경우 공통적으로 사용되는 키워드들(e.g. for, while, if, try, 숫자, 연산기호)가 존재한다. 또 대부분 영어 단어로 구성되므로 많은 공통 단어를 갖고 그래서 cross-lingual 하다. 모델의 Cross-linguality는 언어 간 공통적으로 등장하는 토큰 수에 의존한다. 예를 들어, English-French XLM 모델은 English-Chinese 모델보다 공통 알파벳을 사용해서 더 좋은 cross-lingual representation을 갖는다.
2. (DAE) Denoising auto-encoding

XLM 사전학습이 끝나면 인코더-디코더 모델을 구현할 수 있다. 4.1. 절에서 학습한 XLM pre-training을 인코더로 사용하여 입력 sequence의 high quality representation 생성한다.
DAE는 번역 모델의 인코더-디코더 성질을 이용한다. AE(Auto-Encoder, 오토 인코더)는 입력을 받아 같은 값을 출력해주는 모델로 쉬운 태스크이다. 따라서 AE에 단순히 복사 작업을 지시하는 대신, 노이즈를 섞어준 소스 문장을 입력으로 주어졌을 때 노이즈가 제거된 복원된 문장을 출력하도록 훈련하는 모델을 DAE라 한다.
TransCoder에서 디코더 부분은 트랜스포머 디코더 구조를 이용한다. 하지만 디코더가 source representation을 기반으로 하는 sequence를 디코딩하기 위해 훈련된 적이 없어서 번역 능력이 부족하다. 이 문제를 해결하기 위해 인코더-디코더를 DAE(Denoising Auto-Encoding) 문제로 학습한다.
DAE는 지도학습 기반 번역 알고리즘같이 해당 sequence의 손상된(noisy) 버전이 주어지면 올바른 sequence를 예측하도록 학습한다. 손상된 sequence를 만들기 위해 토큰 마스킹, 토큰 삭제, 토큰 셔플링 적용하여 입력 데이터를 만든다. 디코더의 첫 번째 입력은 output programming language를 알려주는 special token이다(번역에서 사용되는 기법). 파이썬은 <python>, Java는 <java> 식으로 입력한다. 테스트(추론) 시 python sequence는 XLM으로 encoding 되고, C++ start symbol로 C++ sequence를 만든다. 그리고 이때 C++ 번역 코드의 품질은 XLM의 cross-linguality에 의해 좌우된다. 만약 python 함수와 C++ 함수가 인코더에서 동일한 latent represenation에 맵핑되면 디코더는 고품질의 C++함수를 만들어낼 것이다.
위 그림을 보면 맨 왼쪽 Input code에 손상을 시킨 Corruped code가 만들어진다(가운데). 그리고 이를 다시 Input code로 복원하는 학습을 하여 디코더를 학습한다. 이렇게 학습된 DAE는 인코더의 출력이 노이지 해도 디코더는 유효한 함수를 생성할 수 있도록 한다. 인코더가 노이즈 인풋에 강건하게 하고, 나중에 사용할 back-translation에 도움을 준다.
3. Back-translation

BT(Back-translation)은 기존의 훈련된 반대방향 번역기를 사용해 단일 언어 코퍼스를 기계번역에 합성 병렬 코퍼스를 만든 후, 이것을 기존 양방향 병렬 코퍼스에 추가하여 훈련에 사용하는 방식이다. 중요한 점은 기계번역으로 만들어진 합성 병렬 코퍼스를 사용할 때, 반대 방향 번역기의 훈련에 사용한다는 것이다. 사실 번역기를 만들면 하나의 병렬 코퍼스로 두 개의 번역 모델을 만들 수 있다. 예를 들어 한국어와 영어로 이루어진 병렬 코퍼스가 있다면, 자연스럽게 영한 번역기뿐만 아니라 한영 번역기도 얻게 된다. 따라서 이 방법은 이렇게 동시에 얻어지는 두 개의 모델을 활용해서 서로 보완하여 성능을 높이는 방법이다. 번역 모델의 성능을 향상하는데 많은 도움을 주므로 모든 번역회사들이 꼭 사용하는 기법이다.
실제로, XLM pretraining(4.1. 장)과 DAE(4.2.)로도 코드 번역은 가능하지만 품질이 나쁘다. 지도학습이 아니어서 번역을 학습한 적이 없어서이다. 이 문제를 해결하기 위해 BT 기법을 사용한다. BT는 단일 언어 데이터를 활용하여 번역 모델을 향상하는 가장 효과적인 방법이다. 비지도 학습을 위해 source2target 모델은 병렬 코퍼스로 학습된 target2source 모델과 결합된다. target2source 모델은 target sequence를 source sequence로 번역하는 모델이다. 이때 생성된 source는 noisy 하다. 그럼 생성된 noisy source sequence와 target sequence를 병렬 코퍼스로 하여 source2target, target2source 모델에 지도학습을 수행한다.
위 그림에서 보면 Python code를 C++로 변환하는 모델을 이용하여 임의로 생성된 번역된 C++ 데이터를 만든다. 그리고 이 임의로 생성된 C++ 데이터를 다시 본래 Python 코드로 변환하는 모델을 지도학습을 통해 학습시킨다. Python=>C++ 변환 모델이 정확해질수록 C++=>Python 모델의 성능이 더 올라간다. 번갈아 가며 학습하므로 상호 보완적으로 좋아진다.
Experiment
1. Training details
일반 Transformer 6 layer, 8 multi-attention heads 구조 사용하였다. 하지만 임베딩 사이즈는 Transformer-base 모델의 512 보다 2배 큰 1024를 사용하였다.
XLM 학습 시 한 배치에 최대길이 512 token의 단일 언어32개 sequence로 구성하였다. 변환하고자 하는 코드는 512 token 이하로 구성하여야 하고, 이 모델의 치명적인 약점이다. DAE와 BT를 번갈아 가며 학습하였고, 한 배치에 6000 tokens로 구성하였다. Adam, lr=10^-4, pytorch 프레임워크를 이용하였고 속도를 위해 fp16로 양자화하여 32개의 Nvidia V100 GPU로 학습하였다.
2. training data
GitHub public dataset on Google BigQuery(190914)를 이용하였다. 2008년부터 1,200만 명이 넘는 사람들의 3,100만 개의 프로젝트가 있다. 3TB 데이터셋, 한 달에 1TB씩 다운 가능하다. 2.8M 개의 opensource repository
2.1. 데이터 필터링
재배포를 허가하고 가장 많이 사용되는 C++, Java, Python만 선택했다. 코드의 함수 단위의 번역으로 한정하였다. 최대 길이가 512 token이므로 file단위는 불가능하다. file과 class단위와 다르게 함수는 짧으므로 512 token 이내로 맞출 수 있다. 그리고 함수 단위는 테스트가 가능해서 모델의 평가에 용이하다. XLM 학습은 모든 코드 단위로 수행하였고 DAE와 BT는 함수 단위로만 학습했다.
2.2. 함수 추출
함수는 class 함수와 standalone 함수로 나뉘는데 클래스를 인스턴트화 하는 함수는 제외하고 오직 standalone 함수만으로 한정 지었다. C++과 Python은 함수의 50%가 standalone 함수이고 Java는 15%만이 standalone 함수로 비율이 적었다. 아래 그림은 세 언어에 대해 용량과 개수 통계이다. 세 언어를 합친 용량은 744G로 용량이 엄청나서 GPU 서버급으로도 학습하기 힘들다.
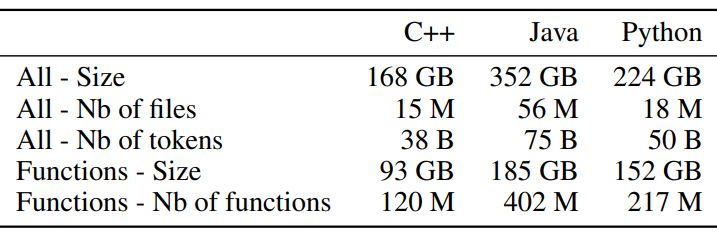
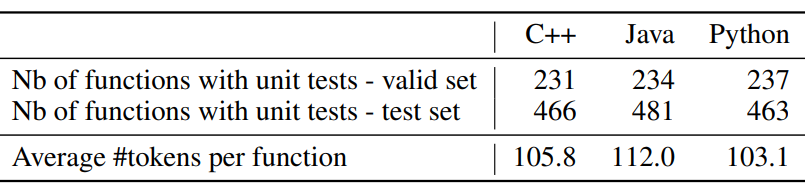
아래 표는 Valid/Test 데이터셋의 개수 통계표이다. 함수당 token 수는 100 이상으로 비슷하다. 최대길이인 512보다 작으므로 너무 긴 함수를 제외하면 문제없을 거라 판단된다.
3. preprocessing

각 언어를 common tokenizer로 분절 후 다중 언어를 섞어서 shared vocabulary를 만들면 vocabulary size를 줄일 수 있고, 언어 사이의 token overlap을 극대화시킬 수 있어 cross-linguality를 높일 수 있다. 그래서 언어별 토크나이즈로 선 분절 후 BPE를 사용한다.
3.1. 언어별 토크나이즈 사용
- C++은 '&&', '||' 기호가 같이 나와서 쪼개지면 안 되지만 파이썬은 한 개씩 나오므로 쪼개져야 한다.
- Python은 indentation(tab)이 아주 중요하지만 C++과 Java는 필요 없다.
- 그러므로 각 언어별 유명한 tokenizer를 이용하여 우선 분절 수행하여 빈 줄, 띄어쓰기 등 제거를 진행한다. 위 그림을 보면 다른 형식의 빈 줄과 띄어쓰기가 있어도 같은 분절 결과를 나타냄을 확인할 수 있다.
- 코드 언어별 토크나이즈
- Python : Tokenizer for Python source(예시 사진 첨부)
- C++ : clang
- Java : javalang
4. Evaluation
평가를 위해 GeeksforGeeks 온라인 플랫폼 사용하였다. 이 사이트는 온라인 코딩 교육 사이트로 많은 코딩 문제와 여러 언어의 정답 제공한다. 이를 통해 parallel functions 수집(Python, C++, Java)하여 validation/test set 구축하였다.
그리고 기계번역의 가장 큰 문제인 평가척도에 대해 분석하고 새로운 평가 척도를 고안하였다. 기계번역 태스크의 성능 측정에 활용되는 BLEU는 n-gram 매치 외에 다른 요소를 무시한다는 큰 단점을 지니고 있다. 사람들은 같은 의미의 문장을 자기만의 방식으로 하듯이 개발자 역시 같은 기능을 하기 위한 코드를 서로 다르게 작성할 수 있지만 이럴 경우 BLEU가 낮다. 또 다른 출력을 내지만 구문적으로 유사하여 BLEU 점수가 높을 수도 있다. 따라서 코드 변환의 경우 레퍼런스 코드(Reference code)와 똑같지 않다고 해도 같은 기능을 하면 높은 점수를 줘야 한다.
즉 BLEU와 레퍼런스 매치 척도는 코드 변환 학습 척도에 적합하지 않다. 그래서 동일한 입력이 주어졌을 동일한 출력이 나오는지를 판단하는 computational accuracy를 제시한다.
Beam search 사용 후 Beam N(N개중 한 개만 맞아도 정답), Beam N-Top 1(N개의 beam 중 가장 높은 확률이 맞는가 아닌가 체크) 두 가지 평가척도로 성능을 확인한다. Beam search의 beam 크기를 늘리는 것이 변환 모델이 유닛 테스트를 통과할 수 있는 코드를 만드는데 많은 성능 향상에 도움이 되었다.
Result

위 그림은 평가 척도에 대한 결과 정리표이다. C++=> Java 변환 모델은 Reference match 평가척도에서 3.1%의 결과 값만이 레퍼런스와 같은 코드를 결과로 내었다. 하지만 60.9%의 결과가 유닛 테스트를 통과하였다. 이를 통해 평가척도의 중요성을 알 수 있다.

위 표는 Beam search는 beam의 크기가 클수록 성능이 좋지만 연산속도는 크기에 비례하여 오래 걸린다. 보통 번역 모델에선5개의 beam을 사용하는데 확실히 위 표를 보면 beam이 가장 큰 25일 때 성능이 좋았다. 하지만 속도를 고려하여 beam이 10인 모델을 선택하는 게 합리적으로 보인다. 상용 모델(baseline)인 j2py와 Tangible Software Solutions의 성능을 압도했다.

위 그림은 언어 변환 간 성공률과 에러에 대해 보여준다. 가장 관심 있는 Python=>C++은 32.2%만이 성공했다. 컴파일 에러는 29%, 런타임 에러는 4.9%였다. 다른 결과를 내는 경우도 32.6%이다. 즉, 성공한 결과와 틀린 결과를 내는 확률을 합치면 65%이다. 65%의 확률로 간단한 수정을 통해 함수를 변환할 수 있다고 결론지을 수 있다. 타임아웃 에러는 무한루프에 빠지는 경우로 Java와 Python 간의 변환에서 15%가 넘게 나타났다.

위 표는 함수 내 함수를 설명하는 주석(docstring)의 유무에 따른 결과 비교이다. 함수 설명 주석을 남기는 데이터가 제거한 데이터보다 좋은 성능을 보였다. 코드 변환 시 설명 주석을 참고해서 변환한다는 것을 알 수 있다.

위 그림은 3개의 언어 token들을 t-SNE 차원 축소를 통해 시각화한 결과이다. 세 언어의 유사한 단어들은 비슷한 곳에 몰려있다. 같은 기능의 token이 같은 임베딩 공간에 있으면 좋은 Cross-lintuality를 가진다고 볼 수 있다.
Conclusion
병렬 코퍼스가 없는 상황에서도 번역기를 만들 수 있는 게 신기하다. 일반적으로 번역모델 개발자들은 병렬 코퍼스가 없는 경우는 드물다. 그리고 없다 해도 단일 언어 코퍼스만으로 번역기를 구축하여 낮은 성능의 번역기를 구축하느니 비용을 들여 병렬 코퍼스를 직접 구축하여 병렬 코퍼스와 대량의 단일 언어 코퍼스를 이용하여 번역기를 구축한다. 하지만 TransCoder는 완벽히 비지도 학습만으로도 고품질 코드 변환기를 개발했다. 이에 비용을 들여 병렬 코퍼스도 구축하여 더 좋은 성능의 코드 변환기를 추천한다. 해킹도구들을 코드 변환기로 변환하여 탐지를 우회하는데 쓰일 수 있다. 또 랜섬웨어 감염 코드도 코드 변환기로 여러 언어로 변환하여 사용될 수도 있다. 하지만 코드 간의 벽을 허물고 프로그래머들을 도와주는 순기능으로 많이 사용될걸 생각한다. 이를 통해 프로그래머가 사라질 거라는 뉴스들이 있다. 하지만 TransCoder는 이 자체만으로는 좋은 성능을 내지 못한다. 개발자가 코드를 변환하는데 '도움'을 주는 존재지 이만으로 해결하는 것은 불가능하다. 그러므로 오히려 프로그래머들에게 많은 일거리와 편리함을 줄 것이다.
'AI > 자연어처리(NLP)' 카테고리의 다른 글
| GPT3 1편) GPT3 이론 파헤치기 (1) | 2022.10.05 |
|---|---|
| XLM, 다언어 임베딩 및 비지도학습 기반 번역 (1) | 2020.10.08 |
| 한국어 자연어처리 1편_서브워드 구축(Subword Tokenizer, Mecab, huggingface VS SentencePiece) (5) | 2020.07.01 |
| 서브워드 분절하기(sentencepiece, bpe, sub-word, bpe-droupout) (2) | 2020.07.01 |
| BERT를 파해쳐 보자!! (7) | 2019.10.29 |



