최근 인공지능 기반 자연어처리는 거대 언어모델 개발로 큰 성공을 거두고 있습니다. 오늘은 GPT3에 대해 알아봅시다.
1. 언어모델(Language Model)
언어모델은 크게 Auto encoding 모델과 Auto regressive 모델 두 종류로 나눌 수 있습니다.
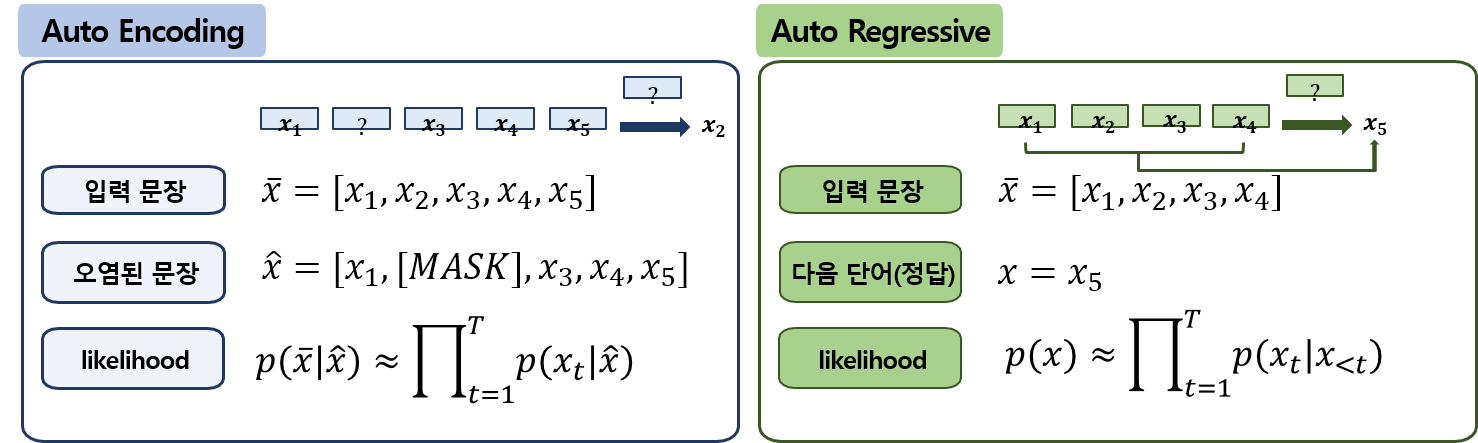

1.1. Auto-Encoding
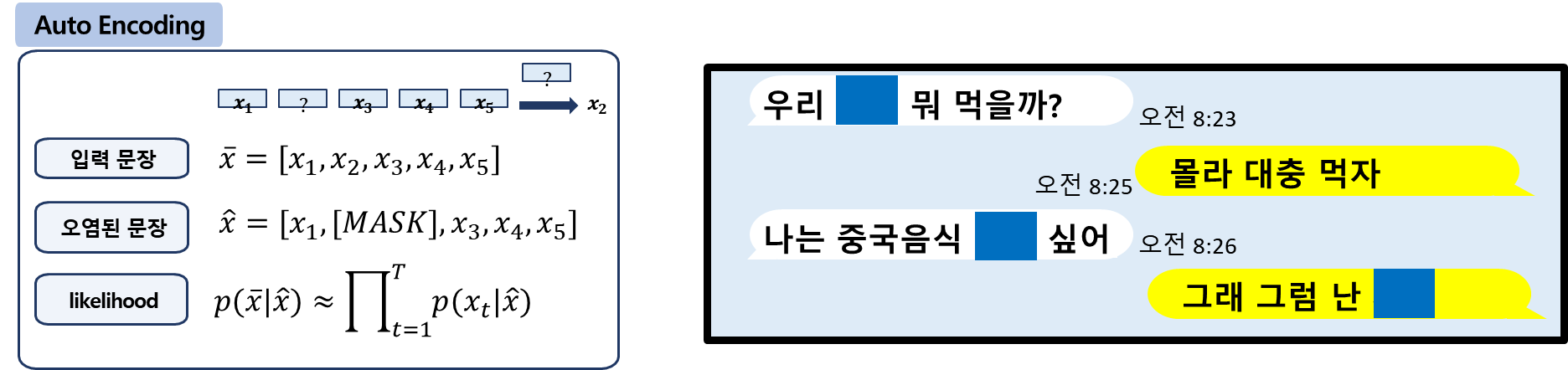
Auto-Encoding 모델은 임의로 문장에서 빈칸([MASK])을 만든 후 주변 단어를 통해 문맥상 빈칸을 맞추는 방식입니다.을 위한 BERT, Electra, RoBerta가 이 방식에 속합니다. 동일 문장이라도 random masking 위치에 따라 서로 다른 정보 학습할 수 있고, Downstream task에 Fine-tuning 시 [MASK] 토큰이 등장하지 않으므로 Pre-training과 Fine-tuning의 학습 목표 불일치 문제가 있습니다.
1.2. Auto-Regressive
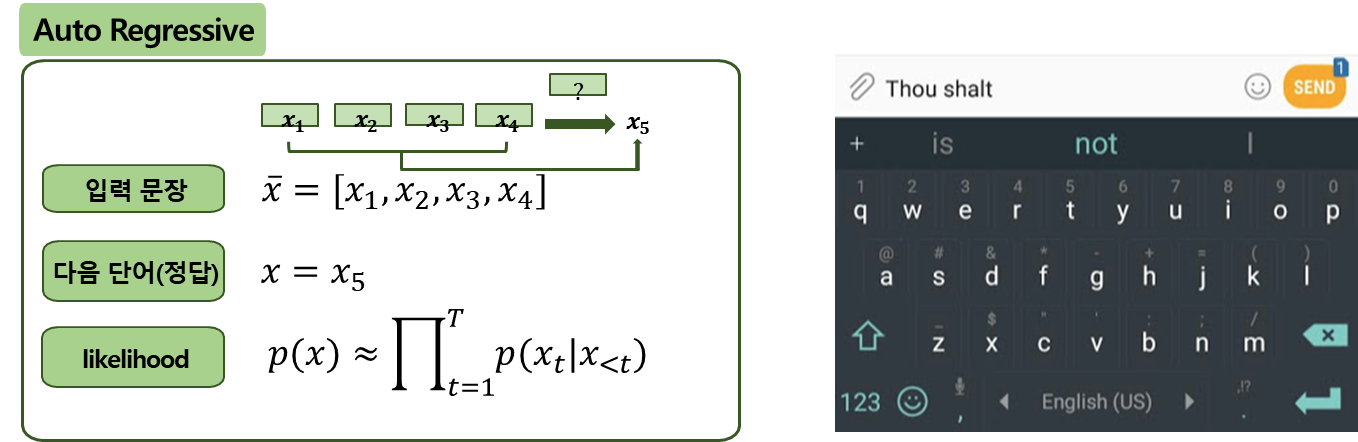
Auto-Regressive 모델은 주어진 연속된 단어의 다음 단어를 맞추는 간단한 방식입니다. 그러므로 동일 문장이면 동일 정보 학습하고 순방향 정보만으로 학습이 가능하므로 양방향 정보 이용이 불가능합니다.모델인 GPT, XLNet이 이 방식에 속합니다.
1.3. 언어모델 입출력

언어모델의 입출력은 위 그림과 같습니다. 입력은 subword 단위로 분절된 token list입니다. 이 token list가 언어모델을 통과하면 token 개수만큼의 embedding vector가 나옵니다. 이때 vector의 size는 언어모델의 크기에 따라 달라집니다. 예를 들어 BERT base 모델은 한 token을 768차원으로, BERT large 모델은 한 token을 1024차원으로 임베딩 합니다.
예를 들어 문장개수x문장길이(token 단위) 입력이 들어갔을 때, 문장개수x문장길이x768 차원의 벡터가 출력됩니다.
2. GPT
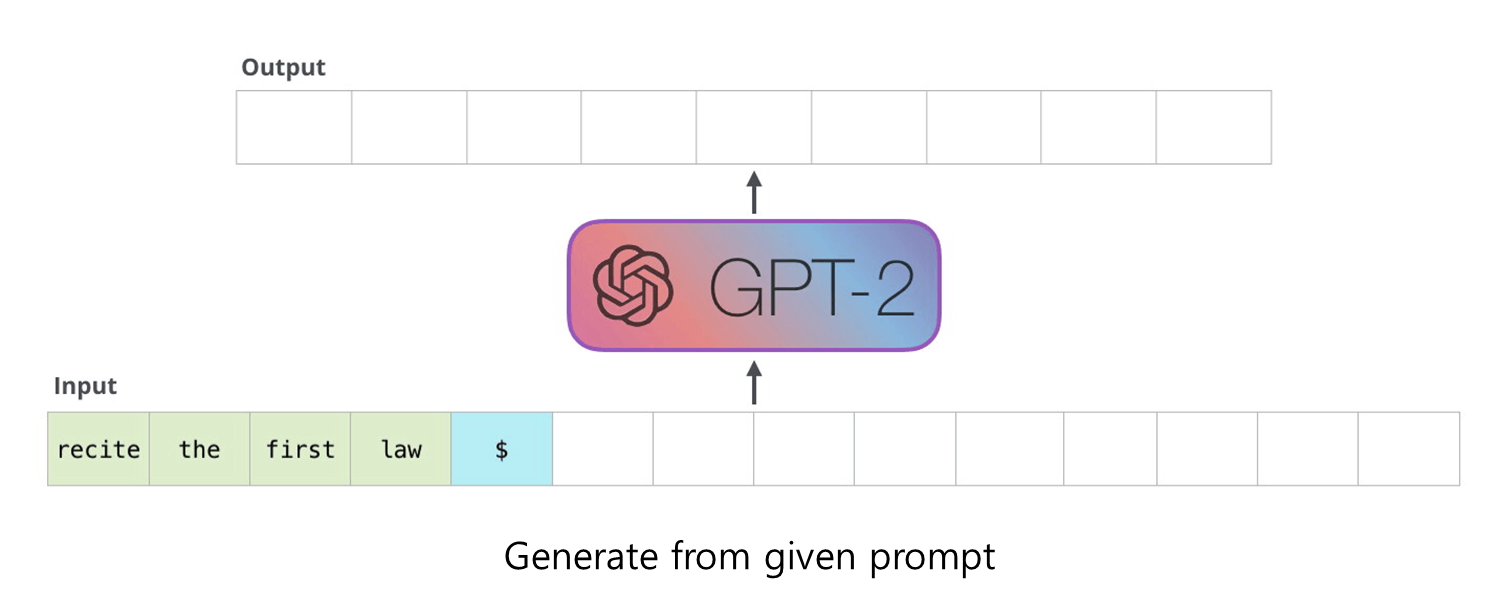
위 그림은 GPT모델의 예시입니다. 연속된 단어가 입력되었을 때, 다음에 올 단어를 맞추고, 이 과정을 반복해서 문장을 완성합니다.
2.1. GPT 구조
GPT는 Transformer(https://arxiv.org/pdf/1706.03762.pdf) 모델을 기반으로 이루어져 있습니다. Transformer는 입력 텍스트를 encoding 하는 encoder, 그리고 encoding 된 vector를 원하는 결과 텍스트로 출력하는 decoder로 이루어져 있습니다. GPT는 이 중 decoder 부분만 띄어내어 사용합니다. encoder만 사용하여 만들어진 모델은 BERT가 있습니다.

encoder와 decoder는 아래 그림과 같이 각각 여러개의 encoder module과 decoder module로 이루어져 있습니다. 즉 각 module을 몇 층을 쌓아서 구성하냐에 따라 모델의 크기가 결정됩니다. 여러층을 쌓아 모델을 크게 만들수록 성능이 좋습니다. encoder와 decoder module은 self-attention block으로 이루어져 있습니다.

2.2. GPT2 모델 크기

GPT2는 모델의 크기에 따라 small(117M), medium(345M), large(762M), extra-large(1,542M) 4가지 모델로 나뉩니다. 이 중 가장 작은 GPT-2 small 모델도 1.1억개의 파라미터를 가지는 매우 큰 모델입니다. 이마저도 일반 기업에서 사용하는 GPU 서버로는 학습이 불가능합니다.

모델 크기는 model dimensionality의 차원과 DECODER 층의 개수로 결정됩니다. Model dimension이 클수록 동일 정보를 많은 벡터로 표현하며, DECODER 층의 개수가 많을수록 깊은 모델입니다.
3. GPT-3
3.1. GPT3 vs GPT2

GPT3는 심지어 이 큰 GPT2 Extra-large(15억) 버전 보다도 100배 이상 큰 1,750억 파라미터로 정말 거대한 모델입니다. 그림으로 비교하면 어마어마하죠?

기존 BERT, XLNet, RoBERTa, T5 보다도 훨씬 거대합니다.
3.2. About GPT3

GPT3는 OpenAI에서 개발한 auto-regressive 형식의 거대 언어모델 입니다.
- GPT3의 새로운 점은 뭐가 있을까요??
- GPT3는 새로운 모델/알고리즘을 제안하지 않았습니다.
- GPT3는 새로운 접근방법도 없습니다.
- 하지만 거대한 언어모델의 새로운 능력(Few-shots learning)을 발견했습니다.
- Few-shots learning에 대한 다양한 실험/평가를 진행합니다.
- 데이터셋
아래 표와 같이 45TB의 텍스트를 전처리하여 570GB의 정제된 텍스트를 얻었습니다.
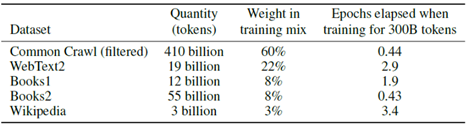
- 기존 언어모델
Downstream task를 수행하기 위하여 대용량 학습데이터로 추가학습(fine-tuning)이 필요합니다.
- GPT3는 어떤 능력??
- 큰 언어모델은 Few shots learning이 가능
- Few shots learning
- 소수의 데이터만으로 학습하는 방법
- Zero-shot: 학습 데이터 0개로 학습
- One-shot: 1개 데이터로 학습
- Few-shot: 소수 데이터로 학습
3.3. GPT3 few shots learning 예시
아래 그림은 GP3의 few shots learning에 대한 예시입니다. 왼쪽은 이전까지 사용되는 traditional 한 방법인 fine-tuning으로 특정 task에 대한 데이터셋을 수집한 후 모델의 gradient update를 통해 원하는 작업을 수행하도록 학습해야만 했습니다.
하지만 GPT3는 그림의 오른쪽과 같이 몇 개의 데이터만 보여주는 few-shots learning을 통해 모델의 weight를 업데이트 하지 않고도 특정 task 수행이 가능합니다. 즉 대량의 데이터가 필요한 fine-tuning과 달리, 몇개의 데이터만을 가지고도 학습이 가능합니다.

Reference
- http://jalammar.github.io/illustrated-gpt2/
- https://medium.com/analytics-vidhya/openai-gpt-3-language-models-are-few-shot-learners-82531b3d3122
- https://papers.nips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- https://youtu.be/MV1l2JPAxVY
- http://dsba.korea.ac.kr/seminar/?pageid=2&mod=document&keyword=nlp&uid=247
'AI > 자연어처리(NLP)' 카테고리의 다른 글
| GPT3 3편) HyperCLOVA(한국어 GPT3), CLOVA Studio 사용후기 (1) | 2022.10.05 |
|---|---|
| GPT3 2편) OpenAI API로 chatbot을 만들어보자! (2) | 2022.10.05 |
| XLM, 다언어 임베딩 및 비지도학습 기반 번역 (1) | 2020.10.08 |
| TransCoder, 비지도학습 기반 프로그래밍 언어 번역기 (0) | 2020.10.08 |
| 한국어 자연어처리 1편_서브워드 구축(Subword Tokenizer, Mecab, huggingface VS SentencePiece) (5) | 2020.07.01 |



