Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
요즘 XLNet이 등장하여 Bert의 기록들을 갱신하고 있다. 자연어 처리 분야에서 Self-Attention을 이용한 모델들이 기존 CNN, RNN을 이용한 모델들보다 크게 성능이 앞서고 있다.
Bert는 Transformer 모델을 기반으로 token을 masking 하고, 다음 문장을 예측하는 2가지 phase를 동시에 적용시킨 모델이다. 하지만 이 모델은 Transformer를 사용하므로, 고정길이의 문장(=512)밖에 다루지 못한다.
즉, Token 길이가 512가 넘는 문장에 대해서는 잘라야 하고, 512가 안 되는 문장은 padding을 해야 한다.
이러한 Transformer의 고질적 한계를 극복하기 위해 구글 브레인에서는 Transformer-XL 모델을 제안한다.
본 글은 구글 브레인에서 2019년 1월, Transformer를 개조하여 고정길이의 문제점을 해결하고 SOTA를 갱신한
Transformer-XL 모델에 대해 다룬다.
github : https://github.com/kimiyoung/transformer-xl
논문 : https://arxiv.org/abs/1901.02860
1. 결과 - language modeling benchmarks
- 5가지 언어 모델링 분야에서 기존 모델들을 큰 차이로 갱신하며 SOTA를 갱신하였다.

2. Requirement
- 파이토치 0.4 이상, 1.1.0v 에서도 잘 동작
3. Data 준비
- 아래 명령어를 입력하면, 모든 language modeling 데이타셋들을한 번에 다운받고 전처리 가능하다. 충분한 저장공간이 필요하다(2G)
- enwik8, one-billion-words, penn pennchar(PTB), text8, wikitext-103, wikitext-2
- >> bash getdata.sh
4. 학습
- transformer-xl/pytorch/ 폴더에
- *large.sh, *base.sh 파일들이 있다. *large.sh 파일로 TPU를 이용한 SOTA를 갱신했고, local GPU로 돌릴 수 없다. *base.sh는몇 개의 GPU로 가능하다.
- TF와 Pytorch 모두 결과가 비슷하다.
- Training & evaluation - 아래 명령어로 학습 시작
- >> bash run_enwik8_base.sh train --work_dir PATH_TO_WORK_DIR
- >> bash run_enwik8_base.sh eval --work_dir PATH_TO_WORK_DIR
- >> bash run_wt103_base.sh train --work_dir PATH_TO_WORK_DIR
- >> bash run_wt103_base.sh eval --work_dir PATH_TO_WORK_DIR
5. Setting
- 기본 Transformer를 돌리고 싶으면
- attn_type=2 and mem_len=0
- mem_len은 얼마나 앞까지볼 거냐, 본 모델은 attn_type=0 and mem_len=512
6. 간단한 정리!!
-
-
기존 모델(Transformer)의 한계
-
기존 모델의 문제점은 고정된 고정 길이 세그먼트에 대해 수행되고, 고정된 컨텍스트 길이의 결과로, 모델은 사전 정의된 컨텍스트 길이를 초과하는 장기 의존성을 캡처할 수 없다.
-
fixed-length segments 문제로 의미 경계를 고려하지 않고, 연속적인 기호 덩어리를 선택하므로, 상황 정보가 부족하여 비효율적이고, 성능 저하(Context fragmentation)
-
-
모델 제안
-
이러한 문제를 해결하기 위해 Transformer XL 모델 제안.
-
각 세그먼트에 대해 숨겨진 상태를 처음부터 계산하는 대신, 이전 세그먼트에서 얻은 숨겨진 상태를 재사용(반복적인 연결을 형성하는 현재 세그먼트의 메모리 역할)하여 기울기 소실 문제를 해결
-
이전 세그먼트에서 정보를 전달하면 컨텍스트 단편화 문제
-
-> 절대적 인코딩(absolute positional embedding) 보다 상대적 위치 인코딩(relative positional encodings)을 사용
-
-
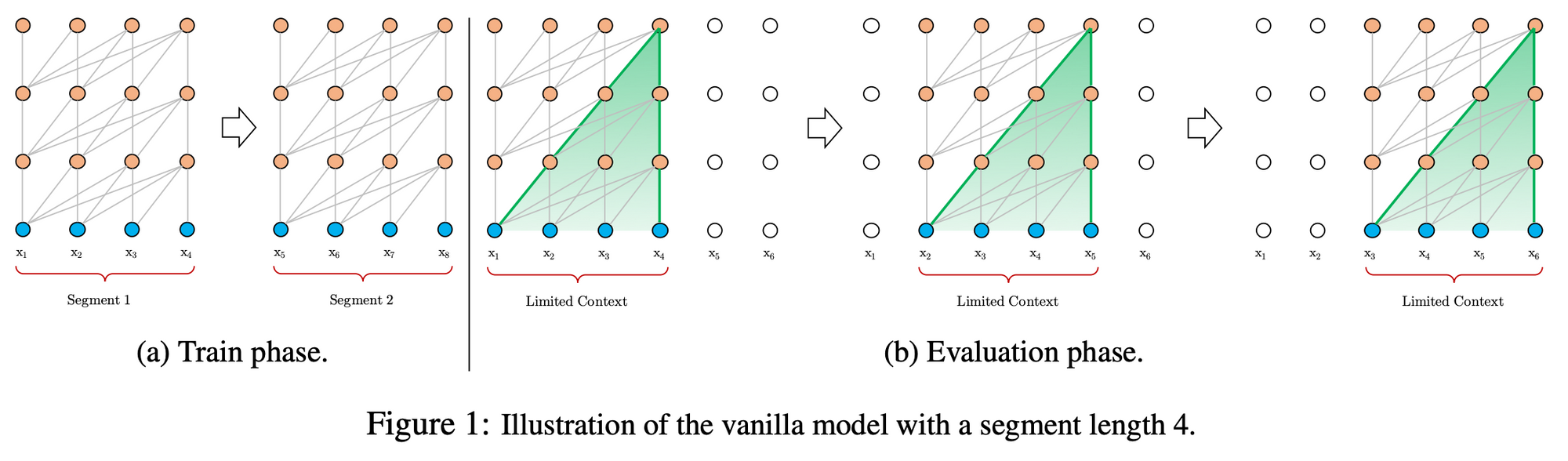
기존모델(Transformer)
-
훈련 시 : 정해진 길이로 Segment를 쪼개고(=4), 1~4(1seg), 5~8 훈련
-
추론 시 : 고정길이씩 sliding 하며 예측, 1~4로 5 예측. 2~5로 6 예측
-
고정길이 딱 4씩밖에 고려하지 않는다
-
-
-
-
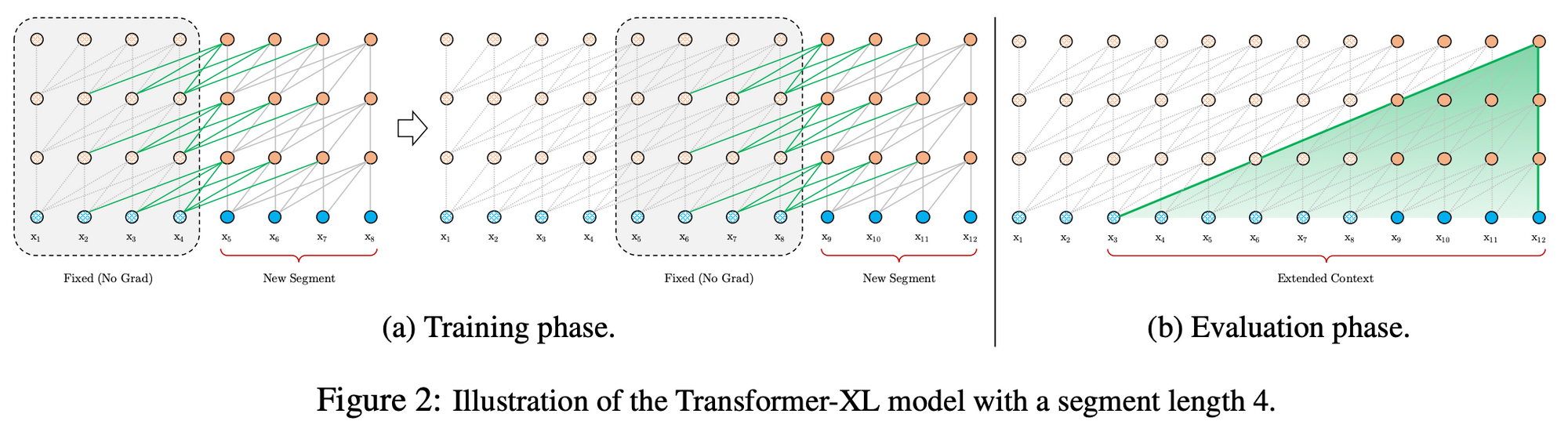
제안 모델(Transformer-XL)
-
훈련 시 : 정해진 길이로 Segment를 쪼개고(=4), 1~4(1seg), 5~8 훈련
-
추론 시 : 고정길이 씩 sliding 하며 예측, 1~4로 5 예측, 2~5로 6 예측
-
고정길이 딱 4씩밖에 고려하지 않는다
-
-
7. 실험 결과
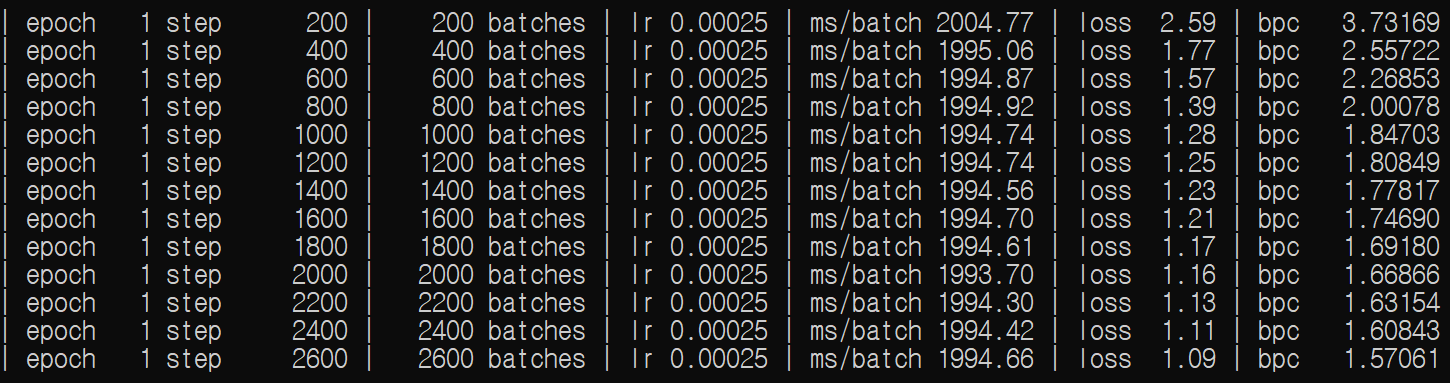
Tesla P100 X 2개를 이용하여 enwik8 데이타에 대해 base 모델을 훈련시켰다.
1 step당 200개의 batch(=22)이고 엄청난 학습시간이 필요할 것으로 판단된다.
bpc가 성능이다. loss는 꾸준히 줄지만 슬슬 수렴하기 시작한다.
Tesla P100 2대를 이용하여 이틀간 학습시켰을 시,
epoch 10, step 72200 만에 Base 모델은 bpc가 1.19까지 떨어졌다.
추측컨데 아무리 오래 돌려도 1.12정도에서 수렴할거라 생각된다.
Base 모델은 Large 모델보다 파라미터 수가 훨씬 적다.
Large 모델로 훈련 시 bpc가 0.99를 기록한 거를 보면 Base 모델과 Large 모델의 차이가 크다는 것을 알 수 있다.
Large 모델은 파라미터가 너무 많아서 배치사이즈를 조정하고 돌려야 한다. 학습시간도 어마어마할거다.
Transformer-XL의 Base 모델을 직접 돌려봄으로써, 얼마나 파라미터가 많고, 학습에 오래 걸리는지, 그리고 Base모델과 Large 모델의 성능차이를 실감했다.
'AI > 자연어처리(NLP)' 카테고리의 다른 글
| TransCoder, 비지도학습 기반 프로그래밍 언어 번역기 (0) | 2020.10.08 |
|---|---|
| 한국어 자연어처리 1편_서브워드 구축(Subword Tokenizer, Mecab, huggingface VS SentencePiece) (5) | 2020.07.01 |
| 서브워드 분절하기(sentencepiece, bpe, sub-word, bpe-droupout) (2) | 2020.07.01 |
| BERT를 파해쳐 보자!! (7) | 2019.10.29 |
| GPT-2 (Generative Pre-Training 2) (2) | 2019.03.26 |


