BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
최근 BERT 라는 이름의 모델이 많은 자연어처리 분야에서 지금껏 state-of-the-art 였던 기존 앙상블 모델을 가볍게 누르며 1위를 차지했다. 특정 분야에 국한된 기술이 아니라 모든 자연어 응용 분야에서 좋은 성능을 내는 범용 모델인 Language model이 탄생하였다. 범용 모델 구조와 대량의 범용 학습 데이터를 사용하여 다양한 task에 flexibility를 높였지만, 많은 자원이 필요하다. 본 글은 BERT에 대한 설명과, 이를 bio, science, finance 등 다른 도메인에 접목시킨 연구들에 대해 다룬다.
1. 서론
BERT는 Bidirectional Encoder Representations from Transformers의 약자로 18년 10월에 논문이 공개된 구글의 새로운 Language Representation Model 이다. NLP의 11개 태스크에 최고 성능을 기록하였다.
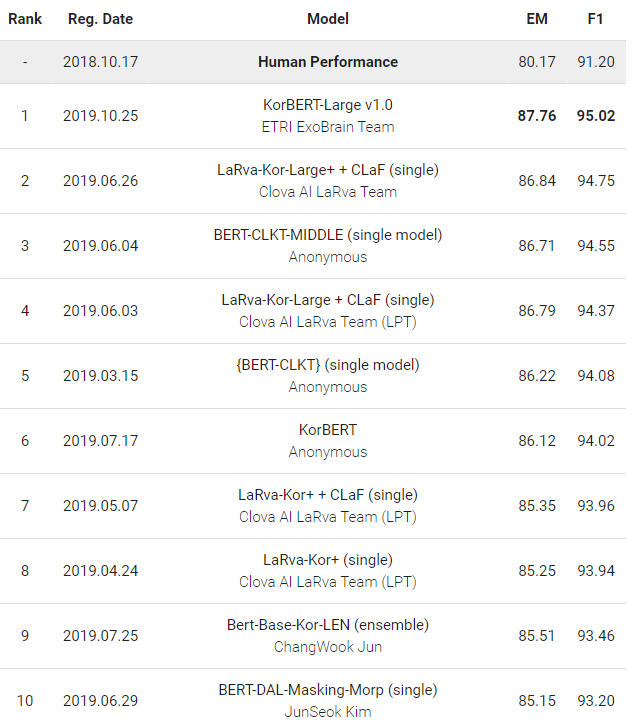
아래 그림은 한국어 QA 대회인 KorQuAD 대회의 성적이다. 19년 10월 현재 1위부터 10위까지 모든 대회 참가자들이 BERT 모델을 이용하여 상위권을 기록하고 있다. 이 모델은 과연 뭐길래 사람의 성능(Human performance)조차 능가하는 것일까?
2. Input Representation
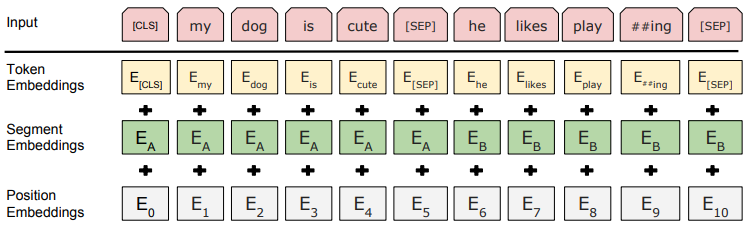
BERT는 위 그림과 같이 3가지의 입력 임베딩(Token, Segment, Position 임베딩)의 합으로 구성된다. 하나하나씩 알아보도록 하자.
1.1. Token Embeddings
BERT는 기존 흔히 사용되는 워드 임베딩 방식의 임베딩을 사용하지 않았다. Word Piece 임베딩 방식을 사용하였는데 이 방식은 자주 등장하면서 가장 긴 길이의 sub-word를 하나의 단위로 만든다. 즉, 자주 등장하는 sub-word은 그 자체가 단위가 되고, 자주 등장하지 않는 단어(rare word)는 sub-word로 쪼개지게 된다. 기존 워드 임베딩 방법은 Out-of-vocabulary (OOV) 문제가 있었다. 희기 단어, 이름, 숫자나 단어장에 없는 단어에 대한 학습, 번역에 어려움이 있었다. 하지만 Word Piece 임베딩은 모든 언어에 적용 가능하며 sub-word 단위로 단어를 분절하므로 OOV 처리에 효과적이고 정확도 상승효과도 있다.
1.2. Sentence Embeddings
BERT는 두 개의 문장을 문장 구분자([SEP])와 함께 합쳐 넣는다. 입력 길이의 제한으로 두 문장은 합쳐서 512 subword 이하로 제한한다. 입력의 길이가 길어질수록 학습시간은 제곱으로 증가하기 때문에 적절한 입력 길이를 설정해야 한다. 한국어는 보통 평균 20 subword로 구성되고 99%가 60 subword를 넘지 않기 때문에 입력 길이를 두 문장이 합쳐 128로 해도 충분하다. 하지만 간혹 긴 문장이 있으므로 우선 입력 길이 128로 제한하고 학습한 후, 128보다 긴 입력들을 모아 마지막에 따로 추가 학습하는 방식을 사용한다.
1.3. Position Embedding
BERT는 저자의 이전 논문인 Transformer 모델을 착용하였다. Transformer은 주로 사용하는 CNN, RNN 모델을 사용하지 않고 Self-Attention 모델을 사용한다. Self-Attention은 입력의 위치에 대해 고려하지 못하므로 입력 토큰의 위치 정보를 줘야한다. 그래서 Transformer 에서는 Sinusoid 함수를 이용한 Positional encoding을 사용하였고, BERT에서는 이를 변형하여 Position encoding을 사용한다. Position encoding은 단순하게 Token 순서대로 0, 1, 2, ...와 같이 순서대로 인코딩 한다.
1.4. 임베딩 취합
BERT는 위에서 소개한 3가지의 입력 임베딩(Token, Segment, Position 임베딩)을 취합하여 하나의 임베딩 값으로 만든다. 그리고 이 합에 Layer Normalization [2]과 Dropout을 적용하여 입력으로 사용한다.
2. 언어 모델링 구조(Pre-training BERT)
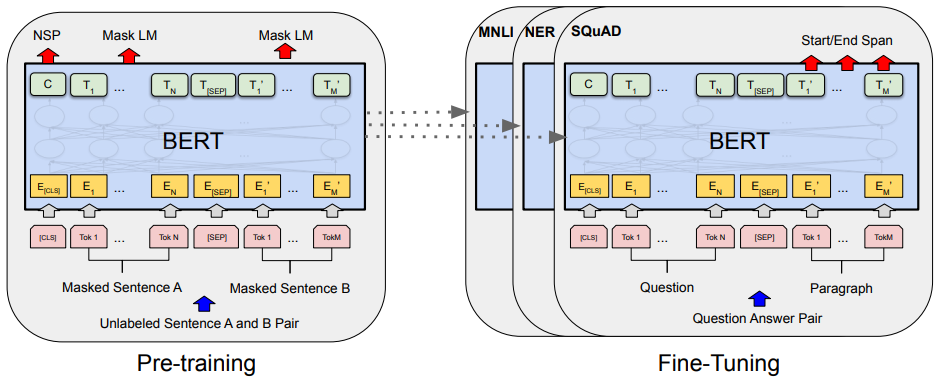
BERT를 이용한 자연어처리는 2단계로 나눈다. 거대 Encoder가 입력 문장들을 임베딩 하여 언어를 모델링하는 언어 모델링 구조 과정과 이를 fine-tuning하여 여러 자연어 처리 Task를 수행하는 과정이다. 본 절에서는 언어 모델링 구조 과정에 대해 다룬다.
기존의 방법들은 보통 좌-우(left-to-right)로 학습하거나 우-좌(right-to-left)로 학습하는 방식이다. 이 방식들은 입력의 다음단어를 예측하는데 좋은 성능을 발휘한다. 하지만 BERT는 이 방식들과 다르게 언어의 특성을 잘 학습하도록 2가지 방식, MLM(Masked Language Model)과 NSP(Next Sentence Prediction)을 사용한다. 기존 방식인 좌-우 언어모델과 비교하여 MLM 방식이 훨씬 좋은 성능을 기록하였다.

2.1. 언어 모델링 데이터
BERT는 총 33억 단어(8억 단어의 BookCorpus 데이터와 25억 단어의 Wikipedia 데이터)의 거대한 말뭉치를 이용하여 학습한다. 거대한 말뭉치를 MLM, NSP 모델 적용을 위해 스스로 라벨을 만들고 수행하므로 준지도학습(Semi-supervised) 학습이라고 한다. Wikipedia와 BookCorpus를 정제하기 위해 list, table, header를 제거하였다. 그리고 문장의 순서를 고려해야 하므로 문단 단위로 분리하였고 많은 데이터 정제 작업을 수행하였다.
2.2. 모델 구조

BERT 모델은 Transformer [1]를 기반으로 한다. 위 그림은 Transformer 모델 구조로 인코더-디코더 모델이며 번역 도메인에서 최고 성능을 기록하였다. 기존 인코더-디코더 모델들과 다르게 Transformer는 CNN, RNN을 이용하지 않고 Self-attention이라는 개념을 도입하였다. BERT는 Transformer의 인코더-디코더 중 인코더만 사용하는 모델이다.
BERT는 2가지 버전이 있다. BERT-base(L=12, H=768, A=12), BERT-large(L=24, H=1024, A=16)이다. L은 Transformer 블록의 숫자이고 H는 hidden size, A는 Transformer의 Attention block 숫자이다. 즉 L, H, A가 크다는 것은 블록을 많이 쌓았고, 표현하는 은닉층이 크며 Attention 개수를 많이 사용하였다는 뜻이다. BERT-base는 1.1억개의 학습 파라미터, BERT-large는 3.4억개의 학습 파라미터가 있다. BERT는 학습 파라미터가 매우 많으므로 학습시간이 무척 오래 걸린다.
2.3. MLM(Masked Language Model)
입력 문장에서 임의로 Token을 마리고(masking), 그 Token을 맞추는 방식인 MLM 학습을 진행한다. 문장의 빈칸 채우기 문제를 학습한다고 생각하면 된다. BERT 이후의 변종들에서 sub-word 단위로 쪼개진 Token을 마스킹 하는게 아니라, 한 단어를 통째로 마스킹 하는 whole word masking 방법을 사용하기도 한다. 한국어는 subword 단위로 쪼개는 방식보다 형태소 단위로 쪼개서 마스킹하는 방식이 더 효과가 좋다고 알려져 있다.
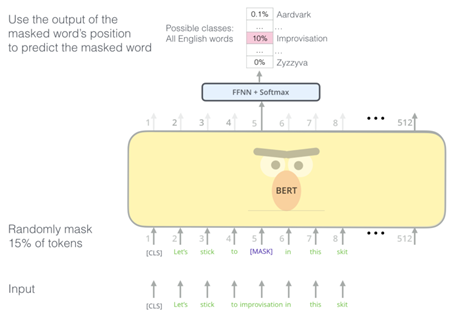
생성 모델 계열은(예를들어 GPT) 입력의 다음 단어를 예측한다. 하지만 MLM은 문장 내 랜덤한 단어를 마스킹 하고 이를 예측하는 차이가 있다. 아래 그림과 같이 입력의 15% 단어를 [MASK] Token으로 바꿔주어 마스킹 한다. 이 때 80%는 [MASK]로 바꿔주지만, 나머지 10%는 다른 랜덤 단어로, 또 남은 10%는 바꾸지 않고 그대로 둔다. 이는 미세 조정 시 올바른 예측을 돕도록 마스킹에 노이즈를 섞는다.
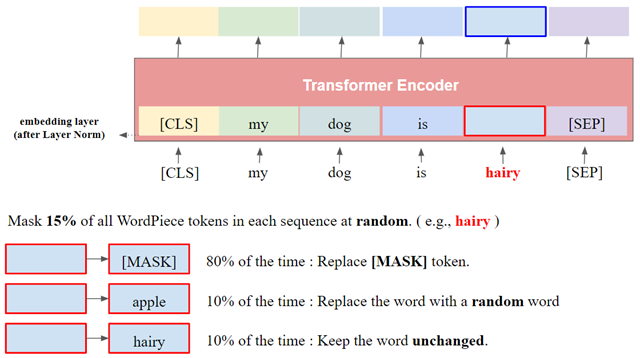
아래 그림은 MLM의 학습 과정이다. 입력 단어의 15%가 [MASK]로 대체된 입력이 들어가고, MLM은 [MASK]가 어떤 단어인지를 예측한다. BERT의 Token 임베딩은 Word Piece 임베딩 방식을 사용하고, Word piece의 단어수는 30522 단어이다. 그러므로 3만 단어 중 [MASK]에 들어갈 단어를 찾는 것이므로 MLM의 출력인 Softmax의 클래스는 3만개 이다.
2.4. NSP(Next Sentence Prediction)
NSP는 두 문장이 주어졌을 때 두 번째 문장이 첫 번째 문장의 바로 다음에 오는 문장인지 여부를 예측하는 방식이다. 두 문장 간 관련이 고려되어야 하는 NLI와 QA의 파인튜닝을 위해 두 문장이 연관이 있는지를 맞추도록 학습한다. 아래 그림은 NSP의 입력 예시이다. 위에서 설명한 MLM과 동시에 NSP도 적용된 문장들이다. 첫 번째 문장과 두 번째 문장은 [SEP]로 구분한다. 두 문장이 실제로 연속하는지는 50% 비율로 참인 문장과, 50%의 랜덤하게 추출된 상관 없는 문장으로 구성된다. 이 학습을 통해 문맥과 순서를 언어모델이 학습할 수 있다.

아래 그림은 NSP의 학습 방법이다. 연속 문장인지, 아닌지만 판단하면 되므로 Softmax의 출력은 2개이고 3만개의 출력을 갖는 MLM에 비해 빠르게 학습된다.

3. 학습된 언어모델 전이학습(Transfer Learning)
미세조정은 3절에서 학습한 언어 모델을 이용하여 실제 자연어처리 문제를 푸는 과정이다. 실질적으로 성능이 관찰되는 것은 전이학습 이지만, 언어 모델이 제대로 학습되야 전이학습 시 좋은 성능이 나온다. 기존 알고리즘들은 자연어의 다양한 Task에 각각의 알고리즘을 독립적으로 만들어야 했다. 하지만 BERT 개발 이후 많은 자연어처리 연구자들은 언어 모델을 만드는데 더 공을 들이게 되었다. 그리고 전이학습 Task의 성능도 훨씬 더 좋아졌다. 전이학습은 라벨이 주어지므로 지도학습(Supervised learning) 이다.
전이학습은 BERT의 언어 모델의 출력에 추가적인 모델을 쌓아 만든다. 일반적으로 복잡한 CNN, LSTM, Attention을 쌓지 않고 간단한 DNN만 쌓아도 성능이 잘 나오며 별 차이가 없다고 알려져 있다.
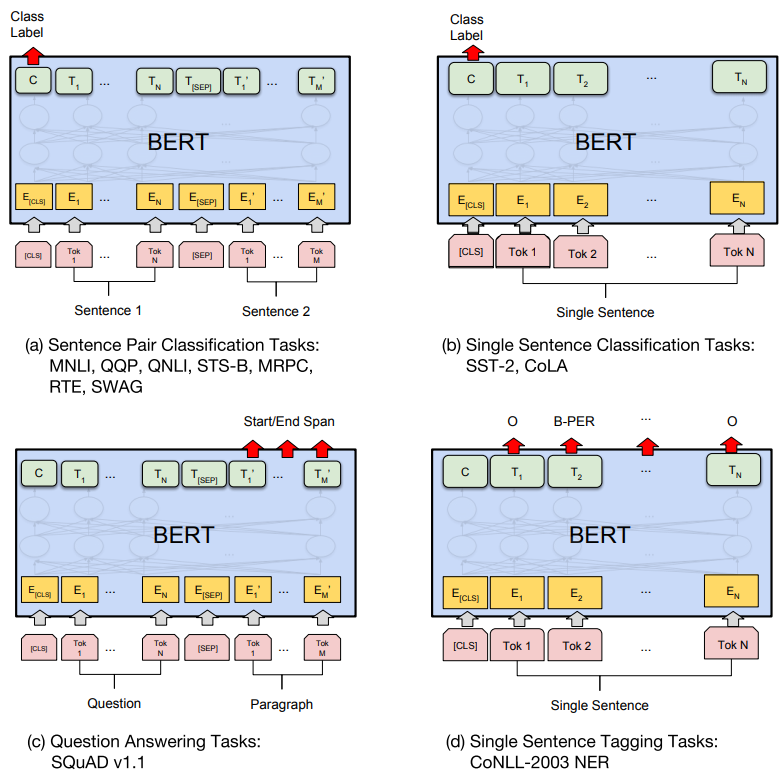
BERT를 각 Task에 쓰기위한 예시는 위 그림과 같다. (a)는 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간 관계를 구한다. (b)는 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제이다. (c)는 문장이나 문단 내에서 원하는 정답 위치의 시작과 끝을 구한다. (d)는 입력 문장 Token들의 개체명(Named entity recognigion)을 구하거나 품사(Part-of-speech tagging) 를 구하는 문제이다. 다른 Task들과 다르게 입력의 모든 Token들에 대해 결과를 구한다.

위 그림은 일반적인 자연어 Task들을 묶은 GLUE 벤치마크 이다. 8개 데이터셋의 평균으로 언어모델의 성능을 비교한다. BERT-base는 기존 SOTA 알고리즘들을 크게 앞질렀고 심지어 파라미터 수가 훨씬 많은 BERT-large는 +8% 정도의 성능 향상을 보여준다.
4. 비교실험
4.1. 학습 방법 비교
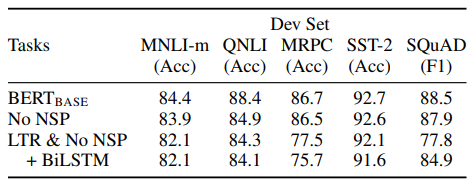
BERT의 2가지 학습방법(MLM, NSP)을 제거해보며 결과를 비교해보았다. No NSP는 MLM만 적용한 방식, LTR & No NSP는 MLM 대신 left-to-right 언어모델 방식으로 학습한 방식이다. left-to-right 방식보다 MLM 방식이 엄청난 성능 향상을 가져왔다. NSP 유무도 NLI 계열의 문제에서 성능이 많이 하락하였다. NSP가 문장간의 논리 구조를 학습하는데 중요함을 알 수 있다.
4.2. 모델 크기 효과
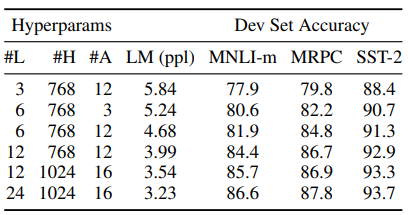
위 그림은 모델 사이즈와 성능에 대한 결과 비교이다. 확실이 모델이 커질수록(L, H, Z) 큰 성능향상이 있었다. 하지만 TPU를 사용하는 구글이 아닌 일반 기업에서는 모델의 사이즈를 무한정으로 키우는건 불가능 하다.
5. 결론
18년 10월 BERT가 발표된 이래로 이를 약간씩 변형한 수많은 모델들이 쏟아져 나오고 있다. 구글, Facebook, MS 등등 엄청난 리소스와 인력으로 일반 기업에서는 시도도 못할 정도이다. 자연어처리 분야가 점점 리소스가 없으면 접근도 할 수 없이 진입장벽이 높아지는 느낌이다. BERT 계열은 훌륭한 성능을 내지만 학습시간이 무척 오래 걸린다. 그리고 BERT는 일반 도메인 데이터로 학습되었기 때문에 일반 자연어처리 문제에서는 무척 잘 동작한다. 하지만 특정 분야(Bio, Science, Finance)에는 잘 동작하지 않는다. 사용 단어들이 다르고 언어의 특성이 다르기 때문이다. 그러므로 특정 분야에 사용하려면 특정 분야의 학습데이터를 수집하여 언어모델 학습을 추가로 진행해 줘야 한다. 하지만 큰 문제가 있다. 이런 학습 데이터를 만들기 위해 수많은 인력과 노력, 시간이 필요하다. 올 한해간 학습데이터를 수집, 정제하고 BERT의 입력데이터 생성에 몇 달의 시간이 걸렸다. 이뿐만 아니라 언어모델 학습에 훌륭한 서버(Tesla V100 X4, 32G)를 사용하여도 한 달의 학습시간이 소요되었다.
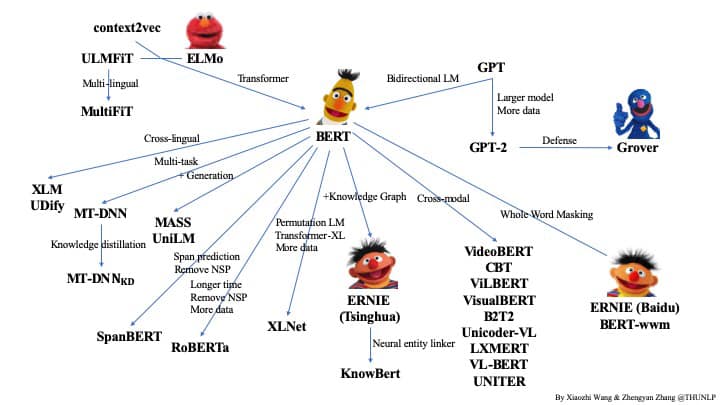
BERT의 성능을 능가하기 위해 더 큰 모델과 학습 데이터를 이용하는 XLNet, RoBERTa 연구가 진행되었지만 학습시간을 줄이기 위해 Floating point 16을 사용하는 방법이나, 모델을 경량화 하는 ALBERT, Knowledge distillation 연구도 활발하게 진행되고 있다.
빠르게 발전하는 자연어처리 모델들을 따라잡는것도 중요하지만 역시 실제 운용을 위한 모델 경량화, 데이터 전처리 작업이 훨씬 더 중요하다.
6. 참조
https://arxiv.org/pdf/1810.04805.pdf
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/1607.06450
http://docs.likejazz.com/bert/
https://mino-park7.github.io/nlp/2018/12/12/bert-%EB%85%BC%EB%AC%B8%EC%A0%95%EB%A6%AC/?fbclid=IwAR3S-8iLWEVG6FGUVxoYdwQyA-zG0GpOUzVEsFBd0ARFg4eFXqCyGLznu7w
https://medium.com/ai-networkkr/%EC%B5%9C%EC%B2%A8%EB%8B%A8-%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5-%EC%86%94%EB%A3%A8%EC%85%98%EB%93%A4-1-%EA%B5%AC%EA%B8%80-bert-%EC%9D%B8%EA%B0%84%EB%B3%B4%EB%8B%A4-%EC%96%B8%EC%96%B4%EB%A5%BC-%EB%8D%94-%EC%9E%98-%EC%9D%B4%ED%95%B4%ED%95%98%EB%8A%94-ai-%EB%AA%A8%EB%8D%B8-9704ebc016c4
http://docs.likejazz.com/bert/
http://jalammar.github.io/illustrated-bert/
https://docs.google.com/presentation/d/1kyflP_nSMGieZ07NTTQJv6Lj1RSabBll57Agxo-qN9w/edit?fbclid=IwAR27G6-PFJ4E1yRRQfdmZH6AA3x7zKpEpAW30Aw4PukzzIC1X_LyW1Uc9Ng#slide=id.g4942b33592_0_285
https://korquad.github.io/category/1.0_KOR.html
'AI > 자연어처리(NLP)' 카테고리의 다른 글
| TransCoder, 비지도학습 기반 프로그래밍 언어 번역기 (0) | 2020.10.08 |
|---|---|
| 한국어 자연어처리 1편_서브워드 구축(Subword Tokenizer, Mecab, huggingface VS SentencePiece) (5) | 2020.07.01 |
| 서브워드 분절하기(sentencepiece, bpe, sub-word, bpe-droupout) (2) | 2020.07.01 |
| Transformer-XL 정리, 사용법 (1) | 2019.07.03 |
| GPT-2 (Generative Pre-Training 2) (2) | 2019.03.26 |


