Intro
llama 언어모델이 공개된 후 Opensource와 상업용으로 이용이 가능한 많은 언어모델이 출시되고 있다. 오늘은 이 중 Databricks에서 공개한 dolly 사용법에 대해 알아보자
Dolly는 pythia 모델에 15,000개의 databricks-dolly-15k(instruction/response 데이터셋)으로 fine-tuning한 모델이다.
databricks-dolly-15k 데이터셋은 Databricks 직원들이 InstructGPT paper를 참고하여 brainstorming, classification, closed QA, generation, information extraction, open QA and summarization들을 포함하는 데이터셋을 만들었다.
dolly-v2-12b: pythia-12b를 기반으로 한 120억 개의 매개 변수를 사용한 모델
dolly-v2-3b: pythia-2.8b를 기반으로 한 28억 개의 매개 변수를 사용한 모델
databricks-dolly-15k 데이터셋 예시
{"instruction": "Why can camels survive for long without water?", "context": "", "response": "Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time.", "category": "open_qa"}
{"instruction": "Why mobile is bad for human", "context": "", "response": "We are always engaged one phone which is not good.", "category": "brainstorming"}
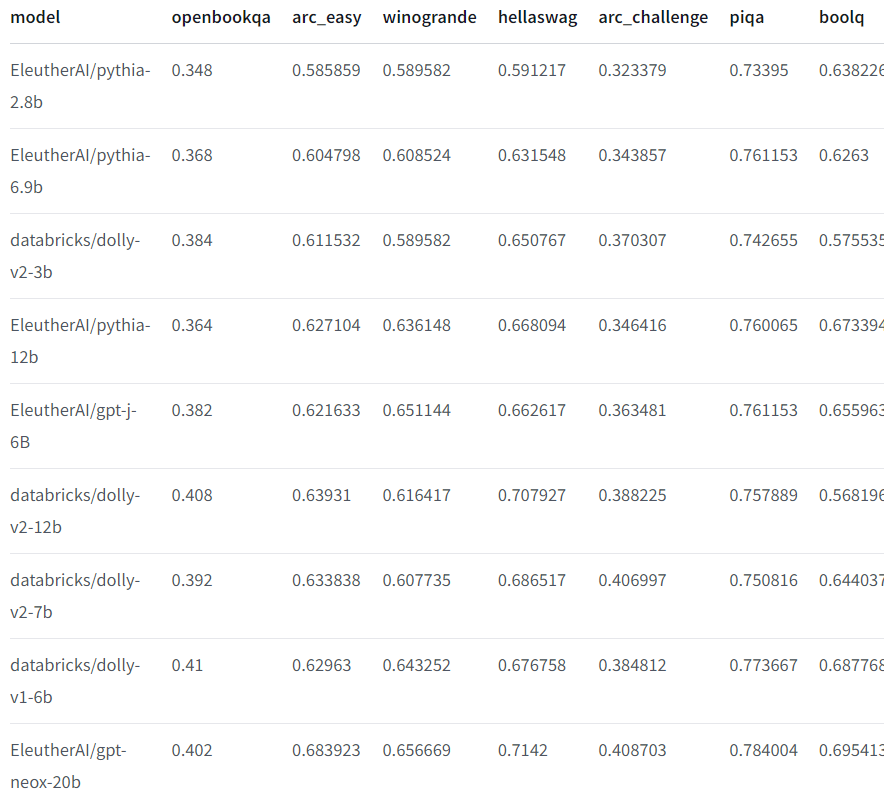
모델 성능은 아래와 같다. EleutherAI의 pythia, gpt-j, gpt-neox와 비교이다.
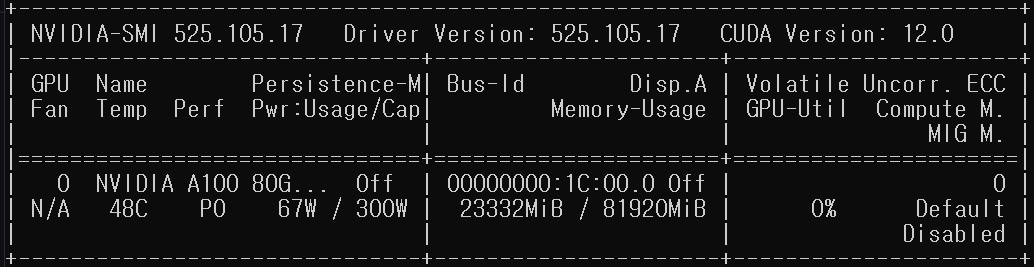
모델 크기별 GPU 사용량 비교
- 12B
- 모델 파일 크기: 24GB
- GPU 메모리 크기: 24GB

- 7B
- 모델 파일 크기: 14GB
- GPU 메모리 크기: 14.5GB


- 3B
- 모델 파일 크기: 6GB
- GPU 메모리 크기: XXGB

사용법
## 1) 설치
# install
%pip install "accelerate>=0.16.0,<1" "transformers[torch]>=4.28.1,<5" "torch>=1.13.1,<2"## 2) 모델 선택 (pipeline 사용)
import torch
from transformers import pipeline
# generate_text = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
# generate_text = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device=0)
# generate_text = pipeline(model="databricks/dolly-v2-7b", torch_dtype=torch.bfloat16, trust_remote_code=True, device=0)
generate_text = pipeline(model="databricks/dolly-v2-3b", torch_dtype=torch.bfloat16, trust_remote_code=True, device=0)## 3) text 생성
res = generate_text("Explain to me the difference between nuclear fission and fusion.")
print(res[0]["generated_text"])## 4) 모델 직접 (pipeline 사용)
import torch
!wget https://huggingface.co/databricks/dolly-v2-3b/raw/main/instruct_pipeline.py
from instruct_pipeline import InstructionTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
# model_name = "databricks/dolly-v2-12b"
# model_name = "databricks/dolly-v2-7b"
model_name = "databricks/dolly-v2-3b"
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.bfloat16)
generate_text = InstructionTextGenerationPipeline(model=model, tokenizer=tokenizer)## 5) text 생성
res = generate_text("Explain to me the difference between nuclear fission and fusion.")
print(res[0]["generated_text"])
Langchain 연동

import torch
from transformers import pipeline
# model_name = "databricks/dolly-v2-12b"
# model_name = "databricks/dolly-v2-7b"
model_name = "databricks/dolly-v2-3b"
generate_text = pipeline(model=model_name, torch_dtype=torch.bfloat16,
trust_remote_code=True, device_map="auto", return_full_text=True)
from langchain import PromptTemplate, LLMChain
from langchain.llms import HuggingFacePipeline
# template for an instrution with no input
prompt = PromptTemplate(input_variables=["instruction"],
template="{instruction}")
# template for an instruction with input
prompt_with_context = PromptTemplate(
input_variables=["instruction", "context"],
template="{instruction}\n\nInput:\n{context}")
hf_pipeline = HuggingFacePipeline(pipeline=generate_text)
llm_chain = LLMChain(llm=hf_pipeline, prompt=prompt)
llm_context_chain = LLMChain(llm=hf_pipeline, prompt=prompt_with_context)
# example 1
print(llm_chain.predict(instruction="Explain to me the difference between nuclear fission and fusion.").lstrip())>> Nuclear fission is the splitting of a large nucleus into smaller nuclei. For example, the fission of a uranium atom into two smaller nuclei. The end result is the release of energy.
Nuclear fusion is the joining of very heavy nuclei into even bigger nuclei with even more mass and binding energy. This reaction releases massive amounts of energy.
Nuclear fission and nuclear fusion are different processes and do not occur at the same time. Nuclear fission happens when a heavy nucleus is split into smaller pieces, while nuclear fusion occurs when two light nuclei slam into each other and form two even lighter nuclei.
# example 2
context = """George Washington (February 22, 1732[b] – December 14, 1799) was an American military officer, statesman,
and Founding Father who served as the first president of the United States from 1789 to 1797."""
print(llm_context_chain.predict(instruction="When was George Washington president?", context=context).lstrip())>> George Washington was president from February 22, 1732 until December 14, 1799.
Reference
- https://github.com/databrickslabs/dolly
- https://huggingface.co/databricks/dolly-v2-3b
- https://huggingface.co/databricks/dolly-v2-7b
- https://huggingface.co/databricks/dolly-v2-12b
- https://github.com/databrickslabs/dolly/tree/master/data
'AI > 자연어처리(NLP)' 카테고리의 다른 글
| GPT3 3편) HyperCLOVA(한국어 GPT3), CLOVA Studio 사용후기 (1) | 2022.10.05 |
|---|---|
| GPT3 2편) OpenAI API로 chatbot을 만들어보자! (2) | 2022.10.05 |
| GPT3 1편) GPT3 이론 파헤치기 (1) | 2022.10.05 |
| XLM, 다언어 임베딩 및 비지도학습 기반 번역 (1) | 2020.10.08 |
| TransCoder, 비지도학습 기반 프로그래밍 언어 번역기 (0) | 2020.10.08 |



